2021. 3. 30. 16:58ㆍComputer vision 논문 & 코드리뷰
Berkeley AI Research (BAIR) Laboratory, UC Berkeley 에서 발행한 논문입니다.
Abstract
image-to-image translation problems에 대한 일반적인 방법부터 Contitional adversarial networks를 사용한 방법까지 조사했다.
Image-to-Image translation problems를 다루는 Networks는 입력 이미지에서 출력 이미지로 가는 mapping을 학습할 뿐만 아니라 loss function도 학습
-> image-to-image translaotion problems에서 각 상황에 따라 사용되는 loss functions이 달랐지만 paper에서 제안한 방식을 적용하면 동일한 loss functions을 사용하여 적용할 수 있다.
이 논문에서 제안한 방법을 사용하면 label maps(?)으로부터 사진을 합성하고 edge maps(경계선만 있는 이미지)에서 object를 reconstruction하고, 흑백 사진을 컬러 사진으로 채색하는데 효과적이다.
실제로 이 paper와 관련된 pix2pix software가 출시된 이후로 많은 아티스트 및 사용자들이 pix2pix software를 이용하여 매개변수를 조정할 필요 없이 광범위한 사용 가능성을 보여준다.
pix2pix는 입력 이미지에서 출력 이미지로 가는 mapping functions을 수작업으로 설계 하지 않고도 합리적인 결과를 얻을 수 있다는 것을 보여준다.
● Introductinon
image processing이나, computer graphics나, computer vision에서의 많은 문제들은 input이미지에서 관련 있는 output이미지로 translating하는 데에 있다고 할 수 있다.
한 개념이 영어와 불어로 둘 다 표현될 수 있듯, 한 장면도 RGB이미지로, gradient field로, edge map으로, semantic label map 등으로 만들어질 수 있다. 자동 언어 번역과 유사하게, paper는 자동 image-to-image translation을 충분한 training data가 주어졌을 때, 한 장면의 하나의 가능한 표현을 다른 표현으로 변환하는 것으로 정의했다.

전통적으로, 그림의 각 task들은 픽셀에서 픽셀을 예측하는 설정이 항상 동일함에도 불구하고 별도의 special-purpose machinery로 처리되었다. 본 논문에서 목표는 이러한 모든 문제에 대한 공통의 프레임워크를 개발하는 것이다.
이미 cnn이 다양한 image prediction problem들에서 workhorse(아주 많은 일을 처리하는 기계)가 되며 이 방향으로 많은 발전이 이루어졌다. cnn은 loss function을 최소화하는 방향을 배우며, learning process가 자동이더라도, 많은 manual efforts(육체적 노력)들이 효과적인 loss를 디자인 하는데 들어간다. (loss function의 중요성 강조)
gound truth pixel과 predicted pixel의 Euclidean distance를 구하는 것 같은 naive한 approach 를 취한다면, 우리는 blurry한 result를 얻을 수 밖에 없다.
CNN이 우리가 정말 원하는 것을 하도록 하는 loss function을 고안하는 것(e.g., output sharp, realistic images)은 열려있는 문제이고, 일반적으로 전문적인 지식을 요구한다.
"output을 현실과 구별할 수 없게 만들기"와 같은 높은 수준(어렵다 보다는 구체적인 이라는 의미 같음)의 목표만 명시한 다음 이 목표를 충족시키는 데 적합한 loss function을 자동으로 학습할 수 있다면 매우 바람직할 것이다.
운 좋게도, 이것은 확실하게 GAN에서 이뤄진 것이다. GAN모델들은 output이 real인지, fake인지 구별하는 것을 시도하는 loss를 학습함과 동시에, generative model이 이 loss를 minimize할 수 있게 학습한다.
GAN은 데이터들에 adapt되는(loss가 사용한 dataset에 맞춰진다는 의미로 생각하면 될 듯) loss를 학습하기 떄문에, 원래 아주 다양한 loss fuctions들을 요구하는 task들에 적용될 수 있을 것 이다.
이 논문에선 conditional setting에서의 GAN들을 탐색. GAN들이 data의 generative한 모델들을 학습함과 같이, conditional GANs(cGANs)는 conditional generative model을 학습한다.
-> input image를 condition하고(길들이고?) corresponding output image를 생성함 = cGANs가 image-to-image변환에 적합'
● Method


● Network architectures
DCGAN의 architecture을 적용하였다
G와 D모두 modules of the form convolution-BatchNorm-ReLu 을 사용 (Details of the architecture are provided in the supplemental materials online, with key features discussed below.)
● Generator with skips
image-to-image translation problems의 정의적 특징은 고해상도 input grid를 고해상도 output grid에 매핑한다는 것이다.
또한, 논문이 고려하는 문제의 경우, 입력과 출력은 표면 외관(surface appearance)은 다르지만, 두 가지 모두 renderings of the same underlying structure이다. 따라서 input의 structure은 output의 structure과 roughly 정렬됩니다. 이러한 고려사항을 중심으로 generator 아키텍처를 설계.
이 영역(GAN)에서의 문제들에 대한 이전의 많은 솔루션들은 encoder-decoder network였습니다.
※ encoder-decoder network: 입력은 bottleneck layer가 될 때까지 점진적으로 downsample시키는 일련의 layers를 통과하며, 이 때 process는 reverse된다.

-> 네트워크는 모든 information flow가 모든 layer를 통과하도록 요구.
이러한 네트워크는 병목 현상bottleneck을 포함한 모든 계층을 모든 information flow가 통과해야 합니다. 많은 image translation problems의 경우, 입력과 출력 간에 공유되는 low-level information가 매우 많으며, 이 정보를 네트워크를 통해 직접 전송하는 것이 바람직할 것이다.
예를 들어, 이미지 컬러화의 경우 입력 및 출력은 두드러진 가장자리(prominent edge)의 위치를 공유합니다.
G에게 이와 같은 정보의 bottleneck을 피할 수 있는 수단을 제공하기 위해(소실되는 데이터를 줄이기 위해), 우리는 "U-Net"의 일반적인 모양을 따라 skip connections를 추가한다. 특히, 각 layer i와 layer n-i 사이에 스킵 연결을 추가한다. 여기서 n은 전체 layer 수이다. 각 스킵 연결은 layer i의 모든 채널과 layer n-i의 채널을 연결하기만 하면 된다.

● Markovian discriminator

전체 이미지에 대한 Low frequency 성분을 L1 regularization term을 통해 파악한 후 High frequency 성분을 잘 보는 PatchGAN D와 결합하는 식(summation)으로 Discriminator의 loss를 구성합니다.
※ 영상처리에서의 high/low frequiency?

이미지가 각 픽셀 대한 개별적 정보를 갖고 있는 것이 아닌 다양한 주파수로 이루어져 있다고 생각합니다.
D가 high frequencies를 모델링하기 위해서는 우리의 attention을 the structure in local image patches에 제한해야 합니다.
PatchGAN의 D는 한 이미지 내의 N x N patch에 대해 real/fake를 구분합니다. N은 특정 픽셀과 다른 픽셀들 간의 연관관계가 존재하는 적절한 범위를 포함해야하기 떄문에 이미지 특성에 따라 결정되는 hyper parameter적인 특성을 가집니다.
이미지 전부를 보고 real/fake판단을 하게되면, G가 D를 속이기 위해 일부 특징을 과장하게 되어 D는 잘 속이지만, 이미지 퀄리티는 낮아질 수 있습니다.
이러한 D (PatchGAN)를 이미지 전체에 걸쳐 복잡하게 실행하고, D의 ultimate output을 위해 ahems response를 평균합니다.
PatchGAN의 patch size는 Discriminator가 가진 convolution layers에 의해 결정되는 Receptive field size에 따라 결정
- PatchGAN의 patch size는 Discriminator가 가진 convolution layers에 의해 결정되는 Receptive field size에 따라 결정됩니다. 즉 PatchGAN D는 G가 만든 이미지 일부를 Crop하는 것이 아닙니다.
- Pix2Pix 논문에서는 256 x 256 크기의 입력 영상과 입력 영상을 G에 넣어 만든 Fake 256 x 256 이미지를 concat한 후 최종적으로 30 x 30 x 1 크기의 feature map(patch size 따라 다르겠죠?)을 얻어냅니다. 이 feature map의 1픽셀은 입력 영상에 대한 70 x 70 사이즈의 Receptive field에 해당합니다.
- 이후 30 x 30 x 1 feature map의 모든 값을 평균낸 후 Discriminator의 output으로 합니다. (‘We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of D.’


section 4.4에서 N이 이미지사이즈에 비해 매우 작아도 결과가 좋음을 입증했습니다.

이러한 D (PatchGAN)은 patch diameter( N )이상으로 분리된 픽셀 간의 독립성을 가정해 이미지를 markov random field로 효과적으로 모델링 한다.
(PatchGAN은 patch의 직경보다 더 멀리 있는 픽셀들은 서로 independent하다는 가정을 깔고 가므로 이미지를 하나의 MRF(Markov Random Field)로 모델링할 수 있게 됩니다.)
->이것이 Imagegan과 patchgan의 확실한 차이
※ markov random field?
- Bayesian modeling 통하여 이미지를 분석하는 데에 사용되는 방법으로, 한 부분의 데이터를 알기 위해 전체의 데이터를 보고 판단하는 것이 아니라 이웃한 데이터들과의 관계로 판단한다.
● Optimization and Inference
- optimization
Generative adversarial nets. 논문에서의 standard한 접근을 따랐다.
D에서 gradient descent 한 스텝, G에서 gradient descent 한 스텝을 번갈아 수행하였습니다.. minibatch SGD를 사용하고 Adam Solver를 적용합니다.
- inference
G를 training시와 완전히 동일한 방식(조건)으로 실행한다.
이것은 test를 할 때에 dropout를 적용한다는 점에서 일반적인 protocol과는 다르다.
그리고 training batch의 집계된 통계가 아닌 test batch의 통계를 사용하여 batch normalization를 적용한다.
batch size가 1로 세팅되어 있을 떄, 이러한 batch normalization으로의 접근은, instance normalization이라 정의되고, image generation task에서 효과적임이 이미 입증되었다.
(experiments 에서는 1~10 사이의 batchsize를 어떤 experiment이냐에 의존하여 사용하였다.)
● Experiments
cGAN의 일반성(generality)을 탐색하기 위해 photo generation과 같은 그래픽 작업과 semantic segmentation과 같은 비전 작업을 포함한 다양한 tast과 dataset에서 이 method를 테스트한다.

- 4.1 Evaluation metrics
perpixel mean-squared error와 같은 기존 메트릭은 결과의 공동 통계(joint statistics)를 평가하지 않으므로 structured losses가 포착을 목표로 하는 바로 그 구조를 측정하지 않는다. (기존 metric사용 x)
두가지 방법을 사용
- “real vs fake” perceptual studies on Amazon Mechanical Turk (AMT) = AMT perceptual studies : colorization이나 photo generation같은 graphics problems 대해서는 human observer의 plausibility(신뢰성)이 보통 궁극적인 목표이므로, map generation과 aerial photo generation, image colorization 대해 이러한 접근 사용 (인력 동원)
- FCN-Score : 합성된 도시 풍경이 off-the-shelf recognition system(이미 완성된, 기성의 인식 시스템)이 그 안에 있는 물체를 인식할 수 있을 만큼 현실적인지 여부를 측정한다. 이 metric은 inception score와 object detection evaluation, semantic interpretability measures와 유사하다.
generative models의 quantitative evaluation는 어려운 것으로 알려져 있지만, 최근 연구는 pretrained semantic classifiers를 사용하여 생성된 자극(stimuli)의 식별성(discriminability) 을 pseudo-metric으로 측정하려고 시도했다. intuition은 생성된 이미지가 사실적인 경우 실제 이미지에 대해 훈련된 semantic classifiers가 합성된 이미지를 올바르게 분류할 수 있을 것이라는 것이다. 이를 위해, 우리는 semantic segmentation을 위해 널리 사용되는 FCN-8s 아키텍처를 채택하고 cityscapes dataset.에서 훈련한다.
그 후에 사진들이 합성되어진 레이블에 대하여 classification accuracy의해 합성된 사진을 채점한다 ( label->photo 문제에서의 이야기인것 같습니다...!)
- 4.2 Analysis of the objective function

어떤 components가 중요할까?를 알기 위해 ablation studies를 진행 (L1term, GAN term을 분리하고, GAN과 cGAN을 비교하기 위해서)

Figure 3은 labels -> photo 문제에서의 quantitive effects를 보여줍니다.
cGAN혼자만의 영향으로 표현된 부분은 람다를 0으로 setting한 것 입니다. -> 조금 더 sharp한 결과를 보여줌을 알 수 있습니다. 그렇지만 특정 부분에서 visual artifacts를 보여줍니다.
람다를 100으로 설정해 L1 + cGAN을 모두 고려한 부분은 이 artifacts를 줄여줍니다.
이 cityscapes labels -> photo task를 관찰한 결과를 FCN-Score로 정량화하였습니다. (Table1)

GAN based objectives가 높은 점수를 달성한 것을 알 수 있습니다. 이것은 합성된 이미지들이 recognizable structure을 더 많이 포함한다 (classifier가 인식을 할만 하게 현실적으로 잘 만들어진 structure들을 많이 포함한다) 는 것을 말합니다.
D에서 conditioning을 제외한 GAN에 대한 test는 loss가 input과 ouput간의 mismatch에 대해 페널티를 받지 않고 오직 output이 realistic하냐만 신경씁니다. 그래서 cGAN에 비해 많이 낮은 FCN score...!
(GAN만 고려한 결과가 figure3에 나와있지 않네요 궁금합니다)
이 경우 (cGAN아닌 GAN) input 이미지와 상관없이 거의 동일한 output을 생성해냅니다.
-> input과 ouput간의 mismatch의 정도를 loss가 측정하는 것이 매우 확실히 중요함을 나타냄
L1 term을 추가하는 것 또한 output이 input을 참조할 수 있게 한다는 것을 알아야 합니다. L1 loss는 ground truth outputs간의 거리에 의해 패널티를 받기 때문입니다. (input과 합성된 output이 잘 match되는지 안되는지 의해)
그래서 L1+GAN 또한 input label maps로 부터 realistic한 이미지를 생성하는데에 효과적이지만, 당연히 L1 + cGAN이 더 성능이 좋겠죠.
Colorfulness
cGANs의 두드러지는 효과는 sharp한 이미지를 생성하고, input label map에서는 존재하지 않는 부분에도 spatial structure를 환각시킵니다(가상의 이미지로 만들어 낸다는 의미로 보면 될 듯 합니다).
그래서 어떤이는 cGAN이 spectral demension(?)에서 sharpening과 비슷한 효과를 낸다고 생각할 수 있을 것 같습니다. (i.e 이미지를 더 colorful하게 만드는 것 )
L1이 edge를 정확히 어디에 위치해야 할지가 불확실할 때 blur을 유발하듯이, cGAN도 픽셀 하나가 취해야 할 몇 가지 그럴듯한 색상 값 중 어느 것이 불확실할 때 평균적이고 회색이 도는 빛을 유발한다.
특히 L1은 가능한 색상보다 conditional probability density function의 median(중간값)을 선택하여 최소화됩니다. 반면에, adversarial loss는 원칙적으로 회색의 출력이 비현실적이라는 것을 인식하게 될 수 있으며, 실제 색상 분포와 일치하도록 장려할 수 있다.
figure 6에서, cGAN이 실제로 Cityscapes 데이터 세트에 이러한 영향을 미치는지 조사한다.
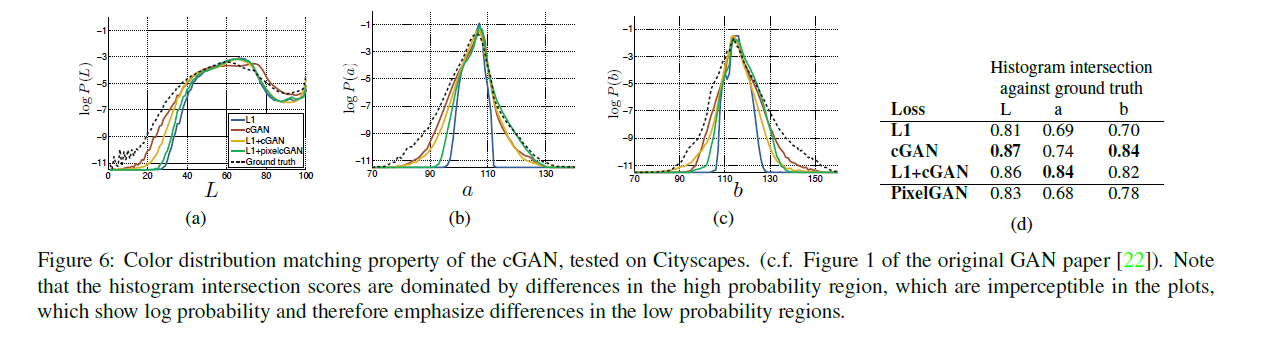
그래프는 Lab color space의 output color values에 대한 주변 분포를 보여 줍니다. 실제 분포는 점선으로 표시됩니다. L1이 평균 회색빛으로 리드한다는 가설을 확인하면서, L1이 실제보다 더 좁은 분포로 이어진다는 것은 명백하다.
반면, cGAN을 사용하여 출력 분포를 ground truth에 가깝게 밀어 넣습니다.

- 4.3 Analysis of the generator architecture
low-level information 의 shortcut 전달을 하게 해주는 U-Net 구조가 정말 효과있는지에 대한 analysis

Figure 4에서 cityscape generation에서 encoder-decoder와 U-Net을 비교합니다.
Encoder-Decoder는 realistic한 이미지를 만들어내지 못하는 결과를 보여줍니다.
cGAN에만 국한되지 않는 U-Net의 장점임을 보여주는 것이, L1만 적용했을 때에도 U-Net이 훨씬 좋은 결과를 보여줌을 볼 수 있습니다.
- 4.4. From PixelGANs to PatchGans to ImageGANs
이 논문의 discriminator의 receptive field인 patch size( N) 을 바꾸는 것의 effect를 테스트 해보았습니다,
1x1 : PixelGAN 에서부터 286x286 : ImageGAN까지.


figure5가 이 analysis의 qualitative result(성능적결과)를 보여주고, table2가 FCN-score를 이용해 이 결과를 정량화하여 보여줍니다.
Q. 그런데 보다보니 Per-class acc는 0.2정도가 최대일 정도로 높지 않은 모습을 보여주고 있는데 ... realistic하다는 증거가 될 수 있을지?
: 아직 gan을 정확히 평가할 수 있는 metric이 없다고 한다. 최근에 fid score나 inception score을 많이 쓰고 있지만, 그것조차 정확하게 gan의 성능을 평가한다고 할 수 없다고 합니다.
<본 논문에서 명시되지 않는 한, 이 section에서 모든 실험은 70 × 70 PatchGAN을 사용하며, 모든 실험은 L1+cGAN loss를 사용한다.>
| PixelGAN ( N=1 ) | spatial sharpness에는 효과 x 결과의 colorfulness는 증가 (figure 5를 보면 L1 loss로 trained되었을 때보다 colorful) image processing에서 color histogram matching은 일반적인 문제이며, PixelGANs는 lightweight solution(용량을 크게 차지하지 않는 해결책?)이 될 수 있다. |
| 16×16 PatchGAN | sharp output을 촉진하는데에 충분 좋은 FCN-score도 달성 가능 하지만 tiling artifacts 유발 (figure 5의 16x16을 보면 이미지가 꼭 타일로 이루어진 것 처럼 네모난 결함들이 있습니다! 아무래도 patch를 사용하여 네모난 부분부분을 attention하고 학습을 시키다보니,, 생길 수 밖에 없는 문제인 듯 합니다.) |
| 70 × 70 PatchGAN | 16x16에서의 tiling artifacts문제를 완화시킵니다. |
| full 286 × 286 ImageGAN (이미지 전체를 참조) | 결과의 visual quality의 향상 x 실제로 FCN score도 더 낮다 -> 아마 ImageGAN이 더 많은 파라미터를 가지고 depth도 더 깊기 떄문에 train이 어려워서일 것이다. |
--> 결국 적당한 N의 선택이 중요(크거나, 작다고 무조건 좋지 않다)
Fully-convolutional translation
PatchGAN의 장점은 fixed-size patch discriminator가 독단적으로 큰 이미지들에도 적용될 수 있다는 것이다.
또한 generator를 훈련 받은 이미지보다 더 큰 이미지에 convolutionally하게 적용할 수도 있다.
- map <-> aerial photo task에 적용
(지도 <-> 공중에서 찍은 사진)
256x256 resolution으로 train된 generator모델을 512x512 이미지들에 테스트

- 4.5. Perceptual validation
map <-> aerial photo task 와 grayscale->color task에서 result의 perceptual realism을 입증
| map<->photo 에서 AMT experiment 결과 : 확실히 L1 보다 L1+cGAN에서 높은 수치를 보였고, Map->photo 에서 특히 높은 수치 : L1이 blurry result를 유발하기 때문 : photo→map 에서는 낮은 수치를 보이는 것은, minor structural error(작은 구조적 오류)들이 map에서는 더 잘 보이기 때문이라고 보인다.(map은 rigid gemetry를 가지기 때문) |
 |
| ImageNet에서 colorization을 train & test (on the test split introduced by [58, 32].) AMT experiment 결과 : conditional GAN의 결과가 [58]의 L2 Regression과 유사 : 그렇지만 [58]의 full method에 미치지 못함.. ([58]논문을 살펴보아야겠다) ------- 이 task에서는 colorization에 특화된 모델의 성능에는 미치지 못한다는 것으로 이해하면 되겠다. |
 |
- 4.6. Semantic segmentation
cGANs는 output이 매우 detailed or photographic한 경우 효과적
output이 input보다 덜 복잡한 semantic segmentation과 같은 vision problem은 어떨까?
cityscape photo→labels task로 cGAN (with/without L1 loss)을 학습시킴
 |
figure 11에서 결과를 나타내고 있고 table 5에서 그를 정량적으로 표현 : L1 loss 없이 훈련된 cGAN은 이 문제를 나름 괜찮은 accuracy로 해결할 수 있었다. : 우리가 아는 한, 이것은 GAN이 continuous valued variation으로 "이미지"가 아닌 "label"을 성공적으로 생성하는 첫 번째 demonstration이다. : cGAN이 어느정도 성공했음에도(괜찮은 FCN score), table5에서 볼 수 있듯 이 problem 에 가장 적합한 method는 아니다. : vision problem의 경우, 목표(즉, ground truth에 가까운 output 예측)가 graphics tasks보다 덜 모호할 수 있으며(semantic segmentation과 같이 비교적 그래픽 측면에서 detail한 정보가 필요없는 경우를 말하는 듯), L1과 같은 reconstruction losses면 대부분 충분하다(논문의 주장) ------ table5에서 볼 수 있 듯, output 이 덜 detail하고 phothographic하지 않은 이런 task에선, L1의 loss로 충분하고, 심지어 성능이 더 좋다. |
 |
- 4.7. Communitydriven Research
여러 커뮤니티에서 original paper를 뛰어넘어 image-to-image translation task에 적용한 사례들(pix2pix codebase)

● Conclusion
본 논문의 결과는 conditional adversarial networks가 image-to-image translation tasks, 특히 highly structured graphical outputs을 포함하는 작업에 대한 많은 이미지에 promising approach임을 시사한다. 이러한 네트워크는 당면한 작업과 데이터에 adapt된 loss을 학습하여 다양한 setting에서 적용할 수 있게 한다.
'Computer vision 논문 & 코드리뷰' 카테고리의 다른 글
| SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization(CVPR 2020) (0) | 2021.04.13 |
|---|---|
| Pix2Pix code review 코드리뷰 (0) | 2021.04.08 |
| U-GAT-IT (0) | 2021.01.29 |
| Spatially Attentive Output Layer for Image Classification (SAOL)(CVPR 2020) (0) | 2021.01.16 |
| Attention Branch Network: Learning of Attention Mechanism for Visual Explanation(ABN, CVPR2019)요약 (0) | 2021.01.16 |