2021. 4. 8. 14:03ㆍComputer vision 논문 & 코드리뷰
아무래도 Test보다는 Train이 고려할 것이 많다보니 Train 과정 먼저 살펴보겠습니다.
빨간 글씨: 의문점/공부해야할 부분
<Train.py>
1. parser에서 여러 옵션들을 parse해오고, dataset을 만들어 줌
opt = TrainOptions().parse() # get training options
dataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other options
dataset_size = len(dataset) # get the number of images in the dataset.
print('The number of training images = %d' % dataset_size)
ㅇ이 과정에서 TrainOptions class는 train에 필요한 옵션들을 가져오는데, BaseOptions class를 상속하며, BaseOptions의 initialize함수로 parser을 초기화 한 후 train에 필요한 추가적 옵션들을 추가한다.
create_dataset으로 옵션에 맞게 dataset을 load한다.
torch.utils.data에 대해 깊게 이해를 하는 시간을 가져야할 듯 하다
<BaseOptions의 initialize>
def initialize(self, parser):
"""Define the common options that are used in both training and test."""
# basic parameters
parser.add_argument('--dataroot', required=True, help='path to images (should have subfolders trainA, trainB, valA, valB, etc)')
parser.add_argument('--name', type=str, default='experiment_name', help='name of the experiment. It decides where to store samples and models')
parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
parser.add_argument('--checkpoints_dir', type=str, default='./checkpoints', help='models are saved here')
# model parameters
parser.add_argument('--model', type=str, default='cycle_gan', help='chooses which model to use. [cycle_gan | pix2pix | test | colorization]')
parser.add_argument('--input_nc', type=int, default=3, help='# of input image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--output_nc', type=int, default=3, help='# of output image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in the last conv layer')
parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in the first conv layer')
parser.add_argument('--netD', type=str, default='basic', help='specify discriminator architecture [basic | n_layers | pixel]. The basic model is a 70x70 PatchGAN. n_layers allows you to specify the layers in the discriminator')
parser.add_argument('--netG', type=str, default='resnet_9blocks', help='specify generator architecture [resnet_9blocks | resnet_6blocks | unet_256 | unet_128]')
parser.add_argument('--n_layers_D', type=int, default=3, help='only used if netD==n_layers')
parser.add_argument('--norm', type=str, default='instance', help='instance normalization or batch normalization [instance | batch | none]')
parser.add_argument('--init_type', type=str, default='normal', help='network initialization [normal | xavier | kaiming | orthogonal]')
parser.add_argument('--init_gain', type=float, default=0.02, help='scaling factor for normal, xavier and orthogonal.')
parser.add_argument('--no_dropout', action='store_true', help='no dropout for the generator')
# dataset parameters
parser.add_argument('--dataset_mode', type=str, default='unaligned', help='chooses how datasets are loaded. [unaligned | aligned | single | colorization]')
parser.add_argument('--direction', type=str, default='AtoB', help='AtoB or BtoA')
parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
parser.add_argument('--num_threads', default=4, type=int, help='# threads for loading data')
parser.add_argument('--batch_size', type=int, default=1, help='input batch size')
parser.add_argument('--load_size', type=int, default=286, help='scale images to this size')
parser.add_argument('--crop_size', type=int, default=256, help='then crop to this size')
parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
parser.add_argument('--preprocess', type=str, default='resize_and_crop', help='scaling and cropping of images at load time [resize_and_crop | crop | scale_width | scale_width_and_crop | none]')
parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data augmentation')
parser.add_argument('--display_winsize', type=int, default=256, help='display window size for both visdom and HTML')
# additional parameters
parser.add_argument('--epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
parser.add_argument('--load_iter', type=int, default='0', help='which iteration to load? if load_iter > 0, the code will load models by iter_[load_iter]; otherwise, the code will load models by [epoch]')
parser.add_argument('--verbose', action='store_true', help='if specified, print more debugging information')
parser.add_argument('--suffix', default='', type=str, help='customized suffix: opt.name = opt.name + suffix: e.g., {model}_{netG}_size{load_size}')
self.initialized = True
return parser
<TrainOptions의 initialize>
def initialize(self, parser):
parser = BaseOptions.initialize(self, parser)
# visdom and HTML visualization parameters
parser.add_argument('--display_freq', type=int, default=400, help='frequency of showing training results on screen')
parser.add_argument('--display_ncols', type=int, default=4, help='if positive, display all images in a single visdom web panel with certain number of images per row.')
parser.add_argument('--display_id', type=int, default=1, help='window id of the web display')
parser.add_argument('--display_server', type=str, default="http://localhost", help='visdom server of the web display')
parser.add_argument('--display_env', type=str, default='main', help='visdom display environment name (default is "main")')
parser.add_argument('--display_port', type=int, default=8097, help='visdom port of the web display')
parser.add_argument('--update_html_freq', type=int, default=1000, help='frequency of saving training results to html')
parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')
parser.add_argument('--no_html', action='store_true', help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
# network saving and loading parameters
parser.add_argument('--save_latest_freq', type=int, default=5000, help='frequency of saving the latest results')
parser.add_argument('--save_epoch_freq', type=int, default=5, help='frequency of saving checkpoints at the end of epochs')
parser.add_argument('--save_by_iter', action='store_true', help='whether saves model by iteration')
parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
parser.add_argument('--epoch_count', type=int, default=1, help='the starting epoch count, we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>, ...')
parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
# training parameters
parser.add_argument('--n_epochs', type=int, default=100, help='number of epochs with the initial learning rate')
parser.add_argument('--n_epochs_decay', type=int, default=100, help='number of epochs to linearly decay learning rate to zero')
parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
parser.add_argument('--gan_mode', type=str, default='lsgan', help='the type of GAN objective. [vanilla| lsgan | wgangp]. vanilla GAN loss is the cross-entropy objective used in the original GAN paper.')
parser.add_argument('--pool_size', type=int, default=50, help='the size of image buffer that stores previously generated images')
parser.add_argument('--lr_policy', type=str, default='linear', help='learning rate policy. [linear | step | plateau | cosine]')
parser.add_argument('--lr_decay_iters', type=int, default=50, help='multiply by a gamma every lr_decay_iters iterations')
self.isTrain = True
return parser2. 이렇게 받아온 옵션들을 넣어 model을 만들어주고, setup(네트워크 로드 및 네트워크 출력, schedulers 생성)
model = create_model(opt) # create a model given opt.model and other options
model.setup(opt) # regular setup: load and print networks; create schedulers
visualizer = Visualizer(opt) # create a visualizer that display/save images and plots
total_iters = 0 # the total number of training iterationsmodels/__init__.py에 있는 create_model(opt)는 opt.model의 이름을 갖는 모델(BaseModel의 subclass여야 한다)을 찾아 opt의 옵션들을 넣어 instance를 만들어 반환해줍니다. (저희는 pix2pix모델을 사용할 것인데, parser의 --model의 default값이 cyclegan이네요, 코드를 돌릴 때 pix2pix로 바꿔주어야 하겠습니다)
visualizer 는 주석대로 시각화/저장 위한 것이므로 자세한 설명은 하지 않겠습니다.
totla_iters는 일단 0으로 초기화를 해주고, epoch수에 따라 계산해줍니다.
3. epoch수 만큼 반복 - 본격적인 training
opt.epoch_count : 시작 epoch 값
opt.n_epochs: initial lr로 진행하는 epoch수
opt.n_epochs_decay : 선형적으로 lr을 0으로 감소시킬 epoch수 (???)
for epoch in range(opt.epoch_count, opt.n_epochs + opt.n_epochs_decay + 1): # outer loop for different epochs; we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>
epoch_start_time = time.time() # timer for entire epoch
iter_data_time = time.time() # timer for data loading per iteration
epoch_iter = 0 # the number of training iterations in current epoch, reset to 0 every epoch
visualizer.reset() # reset the visualizer: make sure it saves the results to HTML at least once every epoch
model.update_learning_rate() # update learning rates in the beginning of every epoch.
for i, data in enumerate(dataset): # inner loop within one epoch
iter_start_time = time.time() # timer for computation per iteration
if total_iters % opt.print_freq == 0:
t_data = iter_start_time - iter_data_time
total_iters += opt.batch_size
epoch_iter += opt.batch_size
model.set_input(data) # unpack data from dataset and apply preprocessing
model.optimize_parameters() # calculate loss functions, get gradients, update network weights
if total_iters % opt.display_freq == 0: # display images on visdom and save images to a HTML file
save_result = total_iters % opt.update_html_freq == 0
model.compute_visuals()
visualizer.display_current_results(model.get_current_visuals(), epoch, save_result)
if total_iters % opt.print_freq == 0: # print training losses and save logging information to the disk
losses = model.get_current_losses()
t_comp = (time.time() - iter_start_time) / opt.batch_size
visualizer.print_current_losses(epoch, epoch_iter, losses, t_comp, t_data)
if opt.display_id > 0:
visualizer.plot_current_losses(epoch, float(epoch_iter) / dataset_size, losses)
if total_iters % opt.save_latest_freq == 0: # cache our latest model every <save_latest_freq> iterations
print('saving the latest model (epoch %d, total_iters %d)' % (epoch, total_iters))
save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'
model.save_networks(save_suffix)
iter_data_time = time.time()
if epoch % opt.save_epoch_freq == 0: # cache our model every <save_epoch_freq> epochs
print('saving the model at the end of epoch %d, iters %d' % (epoch, total_iters))
model.save_networks('latest')
model.save_networks(epoch)
print('End of epoch %d / %d \t Time Taken: %d sec' % (epoch, opt.n_epochs + opt.n_epochs_decay, time.time() - epoch_start_time))
<models/pix2pix_model.py>
본격적으로 pix2pix를 구현한 코드를 볼 수 있는데요, /models/base_model.py 의 BaseModel을 상속받고 있는 class로 구현되어 있습니다.
class Pix2PixModel(BaseModel):BaseModel은 abc(abstract base class)로,
| <set_input>: unpack data from dataset and apply preprocessing. |
| <forward>: produce intermediate results. |
| <optimize_parameters>: calculate losses, gradients, and update network weights. |
이 세가지 메소드가 @abstractmethod가 subclass가 꼭 구현해야 하는 메소드 이며.
주석에서는 subclass를 생성시 __init__에서 BaseModel.__init__(self, opt)를 꼭 처음에 call해주어야 한다고 하고 있다.
(modify_commandline_options 는 optional 이지만 pix2pixModel 클래스에서는 구현되어있음)
: : 주석 내용 : :
주어진 paired data에서 input images와 output images를 mapping하는 것을 배우는 pix2pix model을 구현한 클래스이며, training 시 '--dataset_mode aligned' dataset 을 필요로 한다고 합니다.
● default
- U-Net getnerator('--netG unet256')
- PatchGAN discriminator('--netD basic')를 사용
- '--gan_mode' : vanilla GAN loss (the cross-entropy objective used in the orignal GAN paper). (vanilla GAN Loss에 대해 공부하기)
1. 일단 __init__함수에서, 위에서 말한 것과 같이 BaseModel의 init을 한번 호출해 줍니다. 이후 pix2pix에 맞게 인스턴스 변수들을 지정해줍니다.
## <BaseModel>의 __init__ ##
def __init__(self, opt):
self.opt = opt
self.gpu_ids = opt.gpu_ids
self.isTrain = opt.isTrain
self.device = torch.device('cuda:{}'.format(self.gpu_ids[0])) if self.gpu_ids else torch.device('cpu') # get device name: CPU or GPU
self.save_dir = os.path.join(opt.checkpoints_dir, opt.name) # save all the checkpoints to save_dir
if opt.preprocess != 'scale_width': # with [scale_width], input images might have different sizes, which hurts the performance of cudnn.benchmark.
torch.backends.cudnn.benchmark = True
self.loss_names = []
self.model_names = []
self.visual_names = []
self.optimizers = []
self.image_paths = []
self.metric = 0 # used for learning rate policy 'plateau'
## BaseModel.__init__(self, opt)호출 이후의 Pix2PixModel의 __init__ ##
# specify the training losses you want to print out. The training/test scripts will call <BaseModel.get_current_losses>
self.loss_names = ['G_GAN', 'G_L1', 'D_real', 'D_fake']
# specify the images you want to save/display. The training/test scripts will call <BaseModel.get_current_visuals>
self.visual_names = ['real_A', 'fake_B', 'real_B']
# specify the models you want to save to the disk. The training/test scripts will call <BaseModel.save_networks> and <BaseModel.load_networks>
if self.isTrain:
self.model_names = ['G', 'D']
else: # during test time, only load G
self.model_names = ['G']
# define networks (both generator and discriminator)
self.netG = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
if self.isTrain: # define a discriminator; conditional GANs need to take both input and output images; Therefore, #channels for D is input_nc + output_nc
self.netD = networks.define_D(opt.input_nc + opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
if self.isTrain:
# define loss functions
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device)
self.criterionL1 = torch.nn.L1Loss()
# initialize optimizers; schedulers will be automatically created by function <BaseModel.setup>.
self.optimizer_G = torch.optim.Adam(self.netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D = torch.optim.Adam(self.netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)보시면 BaseModel의 init으로 옵션으로 옵션들, 사용할 device, 저장할 위치 등 기본적인 내용들을 인스턴스 변수로 지정하고, Pix2Pix init에서 loss, optimizer 등의 모델마다 다르게 지정해줘야 하는 것들을 인스턴스 변수로 지정해줍니다.
| self.loss_names 말 그대로 loss들의 이름을 넣어주겠죠 | G_GAN은 generator의 loss 에서 cGAN loss 부분을, G_L1은 generator의 loss에서 L1 loss 부분을 말합니다. : pix2pix_model.py의 backward_D(self) 함수를 보고 해결! A->B변환에서 fake인 B를 넣었을 때와 real인 B를 넣었을 때를 각 loss를 구해 합쳐서 1/2해 준 것이 최종 D의 loss |
| self.isTrain은 train인지 /test인지 결정해주기 위한 인스턴스 변수인데, train.py에서 True로 정해주는 걸 볼 수 있습니다. |
self.isTrain=True self.model_names에 'G', 'D'모두 넣어줍니다. self.netD에서 discriminator를 정의해줍니다.(cGAN: input/output이미지 모두 필요) |
models/network.py의 define_G, define_D로 Generator와 Discriminator를 정의해 주는 부분 도 볼 수 있습니다.
self.netG = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,
not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
if self.isTrain: # define a discriminator; conditional GANs need to take both input and output images; Therefore, #channels for D is input_nc + output_nc
self.netD = networks.define_D(opt.input_nc + opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)<network.py define_G, define_D>
define_G
| input_nc (int) -- 인풋채널수 | output_nc (int) -- 아웃풋채널수 | ngf (int) -- last conv layer filter 수 (default:64) |
| netG (str) -- the architecture's name: resnet_9blocks | resnet_6blocks | unet_256 | unet_128 (default: resnet_9blocks(???pix2pix.ipynb에서 따로 고쳐주는 부분이 없네요 unet을 사용해야하는 것이 아닌지?)) |
norm (str) -- the name of normalization layers used in the network: batch | instance | none (defualt: instance (normalization)) |
use_dropout (bool) -- if use dropout layers. pix2pix에서 not opt.no_dropout을 넣어주네요! 실행시 따로 지정해주지 않으면 dropout을 적용하지 않는 것 같습니다. |
| init_type (str) -- the name of our initialization method(공부필요) opt.init_type은 [normal | xavier | kaiming | orthogona] 중 하나로 정할 수 있는데 default값은 normal입니다. |
init_gain (float) -- scaling factor for normal, xavier and orthogonal. (default: 0.02) |
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2 |
def define_G(input_nc, output_nc, ngf, netG, norm='batch', use_dropout=False, init_type='normal', init_gain=0.02, gpu_ids=[]):
net = None
norm_layer = get_norm_layer(norm_type=norm)
if netG == 'resnet_9blocks':
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=9)
elif netG == 'resnet_6blocks':
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=6)
elif netG == 'unet_128':
net = UnetGenerator(input_nc, output_nc, 7, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
elif netG == 'unet_256':
net = UnetGenerator(input_nc, output_nc, 8, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
else:
raise NotImplementedError('Generator model name [%s] is not recognized' % netG)
return init_net(net, init_type, init_gain, gpu_ids)get_norm_layer함수 내에서는 다음과 같이 normalization을 수행해주네요, functools를 사용합니다.
elif norm_type == 'instance':
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
ResnetGenerator, UnetGenerator를 사용해 network를 만들어주는데요(resnet은 일반 인코더디코더구조와 비교하기위햐 넣어줌), UnetGenerator만 살펴보겠습니다.
대부분 define_G를 실행할 때 넣어준 것이지만, num_downs만 살펴보면 되겠네요. unet128 : 7, unet_256 : 8 을 넣어주네요.
num_downs가 7일 때 128x128이미지가 bottleneck에서 1x1이 된다고 나와 있네요. 다음 그림을 참조하면 좋을 것 같습니다.
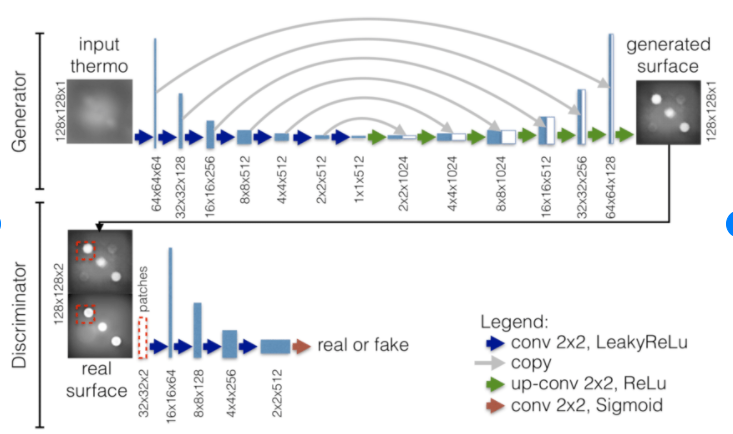
전형적인 nn.Module을 상속한 pytorch의 neural network 구현입니다.
이 내에서 사용 되는 UnetSkipConnectionBlock또한 network.py내의 class(nn.Module상속)입니다. skip connection을 가진 unet submodule을 정의한 class인데요, 자세한 코드 내용은 github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/networks.py 를 참고하시면 됩니다.
class UnetSkipConnectionBlock(nn.Module):
...
def __init__(self, outer_nc, inner_nc, input_nc=None,
submodule=None, outermost=False, innermost=False, norm_layer=nn.BatchNorm2d, use_dropout=False):
...innermost, outermost-> 가장 안쪽, 가장 바깥쪽 layer
outer_nc (int) -- the number of filters in the outer conv layer
inner_nc (int) -- the number of filters in the inner conv layer
inner_nc , outer_nc를 인풋채널수, 아웃풋 채널수와 헷갈리지 말기!
input_nc==None이면 input_nc를 outer_nc와 갖게 해주네요
downconv = nn.Conv2d(input_nc, inner_nc, kernel_size=4,
stride=2, padding=1, bias=use_bias)
downrelu = nn.LeakyReLU(0.2, True)
downnorm = norm_layer(inner_nc)
uprelu = nn.ReLU(True)
upnorm = norm_layer(outer_nc)위와 같이 Unet에서의 conv, relu, norm을 설정해줍니다.
- outermost와 innermost 비교 (encoder부분에서 input쪽이 outermost bottleneck쪽이 innermost)
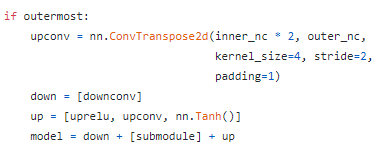

-innermost도, outtermost도 아닌 경우 (default)
dropout은 논문에서 0.5로 사용
else:
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
kernel_size=4, stride=2,
padding=1, bias=use_bias)
down = [downrelu, downconv, downnorm]
up = [uprelu, upconv, upnorm]
if use_dropout:
model = down + [submodule] + up + [nn.Dropout(0.5)]
else:
model = down + [submodule] + up이후
self.model = nn.Sequential(*model)def forward(self,x) 에서도 outermost일때와 아닐 때의 차이가 있네요 -> 아닐 때 skip connection 적용
def forward(self, x):
if self.outermost:
return self.model(x)
else: # add skip connections
return torch.cat([x, self.model(x)], 1)UnetGenerator
class UnetGenerator(nn.Module):
"""Create a Unet-based generator"""
def __init__(self, input_nc, output_nc, num_downs, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False):
"""Construct a Unet generator
Parameters:
input_nc (int) -- the number of channels in input images
output_nc (int) -- the number of channels in output images
num_downs (int) -- the number of downsamplings in UNet. For example, # if |num_downs| == 7,
image of size 128x128 will become of size 1x1 # at the bottleneck
ngf (int) -- the number of filters in the last conv layer
norm_layer -- normalization layer
We construct the U-Net from the innermost layer to the outermost layer.
It is a recursive process.
"""
super(UnetGenerator, self).__init__()
# construct unet structure
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=None, norm_layer=norm_layer, innermost=True) # add the innermost layer
for i in range(num_downs - 5): # add intermediate layers with ngf * 8 filters
unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer, use_dropout=use_dropout)
# gradually reduce the number of filters from ngf * 8 to ngf
unet_block = UnetSkipConnectionBlock(ngf * 4, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
unet_block = UnetSkipConnectionBlock(ngf * 2, ngf * 4, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
unet_block = UnetSkipConnectionBlock(ngf, ngf * 2, input_nc=None, submodule=unet_block, norm_layer=norm_layer)
self.model = UnetSkipConnectionBlock(output_nc, ngf, input_nc=input_nc, submodule=unet_block, outermost=True, norm_layer=norm_layer) # add the outermost layer
def forward(self, input):
"""Standard forward"""
return self.model(input)UnetSkipConnectionBlock의 inner_nc, outer_nc에 ngf * 8, ngf * 4 ..... -> Unet 공부 필요
이렇게 Unet을 구현하는데, innermost ~> outermost 순으로 구현하는 것이 보이네요.
submodule에 이전에 정의한 unet_block을 넣어주며 점점 쌓아줍니다.
inner_nc와 outer_nc(필터수)를 ngf*x에서 ngf까지 점점 줄여주는 것을 볼 수 있네요, 마지막 UnetSkipConnectionBlock을 추가할 땐, outer_nc가 output_nc입니다.(outerlayer의 필터수가 output의 채널 수가 됩니다.)
............................ ......................................
define_D
discriminator을 생성합니다.
| input_nc (int) -- the number of channels in input images | ndf (int) -- the number of filters in the first conv layer | netD (str) -- the architecture's name: basic | n_layers | pixel basic이 default patchgan classifier pixel이 논문에서의 pixelgan이라 보면 되겠다 n_layer? |
| n_layers_D (int) -- the number of conv layers in the discriminator; effective when netD=='n_layers' |
norm (str) -- the type of normalization layers used in the network. | init_type (str) -- the name of the initialization method. (normal/xavier/orthogonal) |
| init_gain (float) -- scaling factor for normal, xavier and orthogonal. | gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2 |
def define_D(input_nc, ndf, netD, n_layers_D=3, norm='batch', init_type='normal', init_gain=0.02, gpu_ids=[]):
net = None
norm_layer = get_norm_layer(norm_type=norm)
if netD == 'basic': # default PatchGAN classifier
net = NLayerDiscriminator(input_nc, ndf, n_layers=3, norm_layer=norm_layer)
elif netD == 'n_layers': # more options
net = NLayerDiscriminator(input_nc, ndf, n_layers_D, norm_layer=norm_layer)
elif netD == 'pixel': # classify if each pixel is real or fake
net = PixelDiscriminator(input_nc, ndf, norm_layer=norm_layer)
else:
raise NotImplementedError('Discriminator model name [%s] is not recognized' % netD)
return init_net(net, init_type, init_gain, gpu_ids)pixceldiscriminator은 비교를 위한 것이므로, basic, n_layers 의 경우에 사용 되는 NLayerDiscriminator 클래스를 살펴뵤자
<models/network.py NLayerDiscriminator>
class NLayerDiscriminator(nn.Module):
"""Defines a PatchGAN discriminator"""
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):
super(NLayerDiscriminator, self).__init__()
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
... (생략)
def forward(self, input):
"""Standard forward."""
return self.model(input)전체적인 흐름을 걸명하자면, 일단 batchnorm일때는 bias를 사용하지 않는데(convolution할 때), 주석에 나온 것 처럼 효율성 측면에서 그렇게 설정한 것이고,
이후
kw에 kernel size 4 를 지정하고 padw 에 padding 1을 지정하여 계속 사용해주는데,
sequence라는 리스트에 conv layer, ReLU layer, normalizatino layer를 계속 추가해줍니다.
(하핳....대충 적은걸 일단 첨부...원래 글씨 이뻐욤,..,.,ㅎ허)
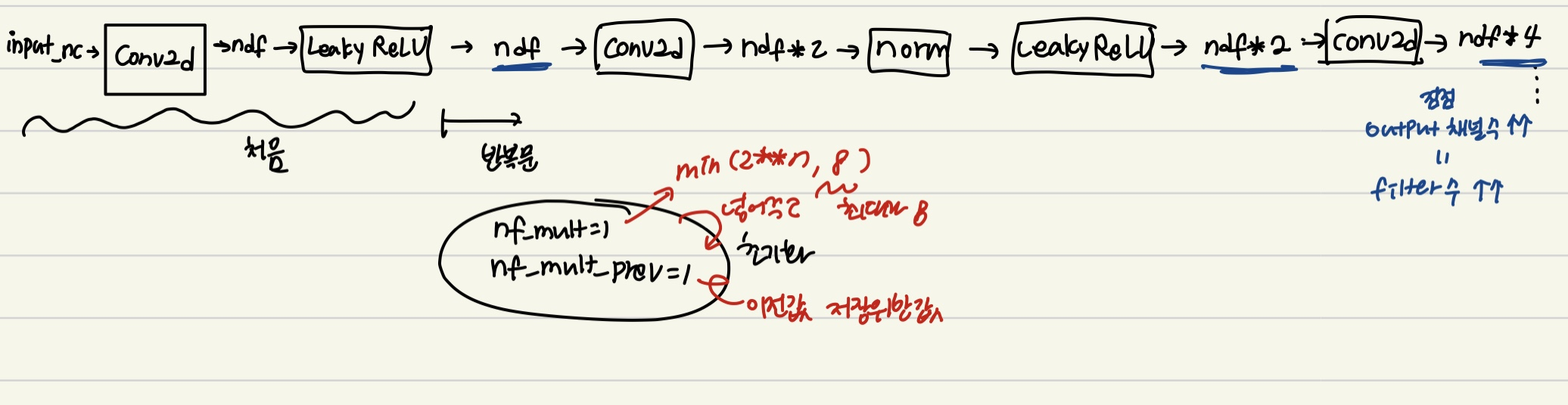
다시 pix2pix_model.py로 돌아와서,
if self.isTrain:
# define loss functions
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device)
self.criterionL1 = torch.nn.L1Loss()
# initialize optimizers; schedulers will be automatically created by function <BaseModel.setup>.
self.optimizer_G = torch.optim.Adam(self.netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D = torch.optim.Adam(self.netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)이 부분은 loss와 optimizer 설정하는 부분이네요.
networks.GANLoss에선 세가지 gan mode(lsgan, vanilla, wgangp)로 self.loss라는 인스턴트 변수에 loss를 구현하여줍니다. lsgan 이 우리가 사용할 cgan loss겠죠
논문에 나온대로 adam optimizer을 사용하네요.
set_input 함수와 forward함수는 간단히 살펴봅니다.
set_input 함수에선 어느방향으로 변환할 것인지 방향을 받아와서, self.real_A는 AtoB일때 A를, self.real_B는 AtoB일 때 B인풋을 말하며, self.image_paths엔 이제 경로를 넣어주는데, set_input함수에 들어가는 input은 dataloader로 생성된 인풋으로, dict형태라서, A, B, A_paths, B_paths등의 key로 데이터를 불러옵니다.(데이터 그 자체와 메타데이터 정보를 가지고 있죠)
forward함수는 당연히 netG에 real_A를 넣은 fake_B를 만들어냅니다.
이제 중요한 backpropagation과 관련된 부분인데요,
def backward_D(self):
"""Calculate GAN loss for the discriminator"""
# Fake; stop backprop to the generator by detaching fake_B
fake_AB = torch.cat((self.real_A, self.fake_B), 1) # we use conditional GANs; we need to feed both input and output to the discriminator
pred_fake = self.netD(fake_AB.detach())
self.loss_D_fake = self.criterionGAN(pred_fake, False)
# Real
real_AB = torch.cat((self.real_A, self.real_B), 1)
pred_real = self.netD(real_AB)
self.loss_D_real = self.criterionGAN(pred_real, True)
# combine loss and calculate gradients
self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5
self.loss_D.backward()
def backward_G(self):
"""Calculate GAN and L1 loss for the generator"""
# First, G(A) should fake the discriminator
fake_AB = torch.cat((self.real_A, self.fake_B), 1)
pred_fake = self.netD(fake_AB)
self.loss_G_GAN = self.criterionGAN(pred_fake, True)
# Second, G(A) = B
self.loss_G_L1 = self.criterionL1(self.fake_B, self.real_B) * self.opt.lambda_L1
# combine loss and calculate gradients
self.loss_G = self.loss_G_GAN + self.loss_G_L1
self.loss_G.backward()input과 output을 모두 고려하는 cgan이니까, fake_AB라는 변수에 real_A와 fake_B를 합쳐서(concat) 사용해주네요.
- backward_D
netD에 fake_AB 넣어 fake인지 예측해보고, cganloss에 pred_fake와 이미지가 fake임을 알려주는 False를 넣어 self.loss_D_fake(fake이미지 넣었을 때의 loss) 생성하고,
real_AB는 real이미지들을 concat해 cgan loss를 계산하여 self.loss_D_real를 생성하는데,
이 두 loss를 1/2하여 최종 D의 loss인 loss_D 계산하며 loss_D.backward()로 backpropagation을 진행합니다.
-backward_G
fake_AB생성은 똑같고, netD에 fake_AB를 넣어 fake인지 예측한 후 cgan loss에 pred_fake를 넣어(이미지가 real이라고 말해줘야함-True) 계산해서 D를 속였는지 확인하고(속였다면 낮은 값이 나오겠죠?)
loss_G_L1은 우리가 논문에서 fake_B, real_B를 모두 넣어 L1 loss 계산한 수 lambda를 곱해준 L1term이네요
이 둘을 더해주어 self.loss_G라는 최종 G의 loss가 나오고, self.loss_G.backward()로 backpropagation을 진행해줍니다.
(netD의 weight들(model parameters)의 requires_grad에 아무런 영향을 주지 않으며 fake_AB 본인의 requires_grad를 False로 만듦-> fake 본인의 grad는 여전히 None이고, detach()에 의해 grad_fn도 None으로 바뀌었기 때문에 netG의 weight들로 backpropagation도 할 수 없다.-> netD만 학습하려는 것 (GAN이 아니라 일반적인 one stage Neural Network에서도 input의 requires_grad가 True일 필요는 전혀 없다. 우리가 학습하려는 것은 오직 model parameters, 즉 weight들이기 때문에 weight Tensor의 requires_grad만 True이면 된다)
optimize_parameters함수에선 D와 G를 update 하는 과정을 구현하고 있습니다.
def optimize_parameters(self):
self.forward() # compute fake images: G(A)
# update D
self.set_requires_grad(self.netD, True) # enable backprop for D
self.optimizer_D.zero_grad() # set D's gradients to zero
self.backward_D() # calculate gradients for D
self.optimizer_D.step() # update D's weights
# update G
self.set_requires_grad(self.netD, False) # D requires no gradients when optimizing G
self.optimizer_G.zero_grad() # set G's gradients to zero
self.backward_G() # calculate graidents for G
self.optimizer_G.step() # udpate G's weights'Computer vision 논문 & 코드리뷰' 카테고리의 다른 글
| SSD: Single Shot MultiBox Detector (0) | 2021.05.05 |
|---|---|
| SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization(CVPR 2020) (0) | 2021.04.13 |
| [Pix2Pix]Image-to-Image Translation with Conditional Adversarial Networks (0) | 2021.03.30 |
| U-GAT-IT (0) | 2021.01.29 |
| Spatially Attentive Output Layer for Image Classification (SAOL)(CVPR 2020) (0) | 2021.01.16 |