2021. 4. 13. 00:17ㆍComputer vision 논문 & 코드리뷰
Google Research, Brain Team 에서 발행한 논문이네요.
- Abstract
CNN은 일반적으로 input image를 해상도가 감소하도록 encoding합니다. -> 분류 작업에는 적합 but 인식 +localization (object detection)에는 적합 x
이 문제 해결 위해 encoder-decoder 아케텍쳐는 분류 위해 설계된 backbone model에 decoder network 를 적용
scale-decreased backbone때문에 encoder-decoder 아키텍쳐는 strong multi-scale features를 생성하는데 효과적이지 않음.
-- > SpineNet : a backbone with scale-permuted intermediate features and cross scale connections that is learned on an object detection task by Neural Architecture Search
SpineNet은 ResNet-FPN모델과 유사한 building blocks를 사용하면서, 더 좋은 성능을 보여주면서 FLOP은 10-20% 적게 사용하였다고 한다.
SpineNet-190은 COCO에서 52.1% AP를 달성하여 test-time augmentation 없이 single model object detection 를 위한 새로운 최첨단 성능을 달성한다.
SpineNet은 classification tasks으로 적용하여 까다로운 iNaturalist 세분화된 데이터 세트에서 5%의 상위 1위 정확도 향상을 달성할 수 있다.
- introduction
CNN 설계의 발전에 비해, meta architecture design은 CNN 발명 이후 변경되지 않음. 대부분의 Network가 단순히 감소된 해상도의 intermediate features로 input이미지를 encoding.
CNN의 가장 큰 개선은 network depth를 늘리고, feature resolution grouop내의 connection을 추가하는 것.
scale-decreasedd architecture design의 motivation : 형상의 존재를 감지하기 위해서는 고해상도(high resolution)가 필요할 수 있지만, 형상의 정확한 위치를 동등하게 높은 정밀도(precision)로 결정할 필요는 없다.
↓but
- scale-decreased model은 recognition + localization (e.g., object detection and segmentation)이 모두 중요한 작업에 strong features를 전달해주지 못할 수 있음.
- scale-decreased model에서 top-level features를 직접 사용하면 low feature resolution으로 인해 small objects detection에 적합하지 않음.
scale-decreased network는 encoder로 간주, backbone model로 언급
보통 앞에서 말한 문제를 해결하기 위해 decoder network에서 backbone에서 low level과 high level features를 결합해 multi scale feature maps를 생성하는 일련의 cross-scale connections로 구성되는데, 보통 backbone 모델이 decoder모다 파라미터나 연산이 더 많기 때문에, decoder(ex. FPN)는 동일하게 유지하면서 backbone모델(ex.ResNet)의 크기를 늘리는 것이 강력한 encoder-decoder model을 얻기위한 일반적인 전략입니다.
하지만,
scale-decreased network는 down sampling을 통해 공간 정보를 버리기 때문에 decoder 네트워크에 의한 복구가 어렵다. 이를 고려하여, backbone 아키텍처 설계에 대한 두 가지 주요 개선 사항을 가진 scale-permuted model이라고 하는 메타 아키텍처를 제안.
첫째, scales of intermediate feature maps는 모델이 더 깊어질수록 공간 정보를 유지할 수 있도록 언제든지 증가하거나 감소할 수 있어야 한다.
둘째, feature maps 간의 연결은 multi-scale feature fusion을 용이하게 하기 위해 feature scales를 통과할 수 있어야 한다.

possible instantiations ∝ combinatorially with the model depth
design choices를 너무 많이 수동으로 하지 않게 하기 위해서, NAS(Neural Architecture Search)를 활용하여 아키텍처를 학습
backbone model 은 the object detection task in COCO dataset에서 학습.(pretrained)
최근 NAS-FPN의 성공에 영감을 받아, simple one-stage RetinaNet detector를 실험에 사용한다.
NAS-FPN에서 FPN를 학습하는 것과 대조적으로, 우리는 backbone model architecture를 학습하고 이를 다음 classification 및 bounding box regression subnet에 직접 연결.
= backbone 모델과 decoder 모델 사이의 구분을 제거한다(end-to-end?).
The whole backbone model can be viewed and used as a feature pyramid network.
ResNet-50 backbone을 baseline으로 사용 + ResNet-50의 bottleneck blocks를 candidate feature blocks로 사용
(1) permutations of feature blocks과 (2) 각 feature block에 대한 두 입력 연결을 학습한다.
candidate model을 얻기 위해 feature blocks의 정렬을 허용하기 때문에, space search의 모든 candidate models는 ResNet-50과 거의 동일한 연산을 한다.(???)
learned scale-permuted backbone architecture = SpineNet
scale permutation and cross-scale connections 이 object detection을 위한 backbone model구축에 아주 중요

특히 SpineNet은 미묘한 시각적 차이와 지역화된 특징으로 클래스를 구별해야 하는 iNaturalist 세분화된 분류 데이터 세트에서 ResNet을 5%의 상위 1위 정확도로 능가
- Method
제안된 백본 모델의 아키텍처는 fixed stem architecture에 이어 학습된 scale-permuted network로 구성된다.
stem architecture는 scale-decreased architecture로 설계된다.
stem network의 블록은 scale-permuted network를 위한 후보 input일 수 있다.

3.1 Search Space
NAS에서의 신경망은 search space라고 부르는, 사전에 정의한 연산자 및 함수들로 구성된 primitive operations들을 선택 및 조합하여 생성됩니다. 이때 구체적인 연산자의 예시로는 크게 convolution, pooling, concatenation, element-wise addition, skip connection 등등이 있습니다.
Scale permutations: 블럭은 순서가 낮은 상위 블록에만 연결할 수 있기 때문에 블럭의 순서가 중요합니다. intermediate 블록과 output 블록을 각각 permutinig하여 스케일 순열의 search space 을 정의하여 search space size를 (N −5)!5! 으로 만든다. Scale permutations은 나머지 아키텍처를 search하기 전에 먼저 결정됩니다.
Cross-scale connections: search space에서 각 블록에 대해 두 개의 input connections를 정의합니다. 상위 블록은 순서가 낮은 블록이거나 stem network의 블록일 수 있습니다. 여러 feature levels에서 블록을 연결할 때 spatial and feature dimensions를 다시 샘플링해야 합니다.
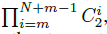
Block adjustments: block의 scale level과 type조정. intermediate blocks는 {−1, 0, 1, 2}만큼 levels를 조정할 수 있고, 그래서 search space 크기는 4^(N-5)가 됩니다. 모든 blocks는 {bottleneck block, residual block} 중 하나의 operation을 선택할 수 있고, 2^N의 search space가 만들어집니다.
3.2. Resampling in Crossscale Connections
cross-scale feature fusion에서는 parent block과 target block간에 resolution과 feature dimension이 다를 수 있는 문제가 있었다. 이를 맞춰주기 위해 Fig4처럼, spatial and feature resampling을 진행한다.




FPN에 이어, 두개의 이렇게 resampled된 input feature map들을 elemental-wise addition(?)과 병합합니다.
3.3. ScalePermuted Model by Permuting ResNet
ResNet architecture의 feature blocks를 permuting함으로써 scale-permuted models를 만듬.
동일한 building blocks을 사용할 때 scale-permuted model 과 scale-decreased model을 공정하게 비교
ResNet의 L5 block을 L6 1개, L7 1개로 replace -> scale-permuted model이 multi-scale output을 생성하게 함.
L5, L6, L7 blocks의 feature dimension은 256으로 set


R[N]-SP[M]을 사용하여 handcrafted stem network의 N개 feature layers와 learned scale-permuted network의 M feature layers를 표시
search space를 scale permutations and cross-scale connections만 포함하도록 제한 -> fair comparison위해
그 다음 reinforcement learning (강화학습) 통해 controller를 train해 model architecture 생성
Nas-fpn과 유사하게, 생성된 아키텍쳐에서 어떤 higher ordering 블록에도 연결하지 않는 intermediate blocks의 경우, 해당 레벨의 출력 블록에 그들을 연결한다.
cross-scale connections는 오직 small computation overhead만 도입한다는 점에 유의(section 3.2)
결과적으로, Figure3 의 모든 모델은 ResNet-50과 유사한 연산을 가지고 있다.
3.4. SpineNet Architectures
ResNet-50 building blocks을 사용하는 것은 building scale-permuted models에 최적의 선택이 아닐 수 있다.
= 최적의 모델은 ResNet과 feature resolution 및 block type distributions 가 다를 수 있다,
--> 섹션 3.1에서 제안한 대로 search space 에 additional block adjustments을 포함
----> 이렇게 학습된 모델 SpineNet-49

SpineNet-96은 각blokc Bk를 두번씩 반복하여 모델 사이즈를 double

4. Applications
4.1. Object Detection
SpineNet architecture는 default ResNet-FPN backbone model을 교체만 하면 RetinaNet detector로 학습된다.
We follow the architecture design for the class and box subnets in [22]
[22]: Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and
Piotr Doll´ar. Focal loss for dense object detection. In ICCV,
2017.
| SpineNet-49S | 4 shared convolutional layers at feature dimension 128 |
| SpineNet-49/96/143 | 4 shared convolutional layers at feature dimension 256 |
| SpineNet-190 | scale up subnets by using 7 shared convolutional layers at feature dimension 512 |
SpineNet은 Mask R-CNN detector에서 backbone model로 사용될 수 있으며 box detection and instance segmentation을 모두 개선할 수 있음.
4.2. Image Classification
SpineNet이 other visual recognition tasks을 일반화할 가능성이 있음을 입증하기 위해 SpineNet을 이미지 분류에 적용.
5. Experiments
object detection -> COCO dataset에 SpineNet적용
train2017 split에서 train, test-dev split에서의 COCO AP로 report main results(그 외에는 val2017 spllit)
For image classification, we train SpineNet on ImageNet ILSVRC-2012 [31] and iNaturalist-2017 [39] and report
Top-1 and Top-5 validation accuracy.
5.1. Experimental Settings
| Training data pre-processing | - For object detection ●(from 640 to 896, 1024, 1280) 더 큰 SpineNet일 수록 더 큰 이미지를 feed. ●그렇게 들어온 이미지는 long side가 target size에 맞게 resize되고 short side는 0으로 padding되어 정사각형이미지가 만들어짐. - For image classification ●use standard scale and aspect ratio data augmentation ●network input is a 224×224 random crop from an augmented image or its horizontal flip ●input image -> normalized by mean and standard deviation per color channel |
| Training details | Figure 3에서 설명한 SpinNet 및 ResNet-FPN 모델을 훈련하기 위해 protocole A로 표시된 동일한 training protocol을 채택하기 위해 [22, 6](Nas-fpn, Focal loss)를 따른다. = stochastic gradient descent(SGD)이용해서 4e-5 weight decay와 0.9 momentum을 가진 Cloud TPU v3 장치에 대해 훈련 모든 모델은 처음부터 - data : COCO train2017 data - batch size: 256 - epochs : 250 epochs - initial learning rate : 0.28 (and a linear warmup is applied in the first 5 epochs.) - 마지막 30, 10epoch에서 0.1×와 0.01×로 감소하는 stepwise learning rate 적용 0.99 momentum 으로 synchronized batch normalization를 적용한 후 ReLU를 적용하고 regularization를 위해 DropBlock을 구현. [0.8, 1.2] 사이의 random scale로 multi-scale training을 적용 base anchor size : SpinNet-96 이하 모델의 경우 3으로, SpineNet-143 or larger models in RetinaNet implementation의 경우 4로 설정 최종 결과를 위해, training protocol protocol B로 나타냄 단순성을 위해 protocol B는 DropBlock을 제거하고 [0.5, 2.0] 사이의 랜덤 스케일로 350eochs 동안 보다 강력한 multi-scale training을 적용한다. large models로 가장 경쟁력 있는 결과를 얻기 위해 stochastic depth를 추가하고 SpinNet-143/190에 대한 swish activation을 protocol C로 표시한다. For image classification, 모든 모델은 200epochs에 대해 4096의 batch size로 train. 처음 5개 epochs에서 learning rate의 linear scaling과 gradual warmup을 가진 cosine learning rate decay를 사용했다. |
| NAS details | architecture search를 위해 recurrent neural network(RNN) based controller구현 -> searching for permutations을 지원하는 유일한 방법으로 알려져있기 때문 reserve 7392 images from train2017 as the validation set for searching. searching process의 속도를 높이기 위해 0.25의 인자로 SpinNet-49의 feature dimension를 균일하게 축소하고, resampling에서 α를 0.25로 설정하고, box and class nets에서 feature dimension 64를 사용하여 proxy SpinNet을 설계한다. search space이 기하급수적으로 늘어나는 것을 방지하기 위해 intermediate blocks을 제한하여 빌드된 마지막 5개 블록 내에서 parent blocks을 검색하고 output blocks가 모든 기존 블록에서 검색할 수 있도록 합니다. At each sample, a proxy task is trained at image resolution 512 for 5 epochs. AP of the proxy task on the reserved validation set is collected as reward. The controller uses 100 Cloud TPU v3 in parallel to sample child models. R35-SP18, R23-SP30, R14-SP39, R0-SP53, SpinNet-49에 가장 적합한 아키텍처는 6k, 10k, 13k 및 14k 아키텍처의 샘플링 후에 발견된다. |
5.2. Learned ScalePermuted Architectures
Fig 3에서, scale-permuted model이 intermediate features들이 지속적으로 up-sample and down sample feature maps 변환을 거치는 permutations을 가지며 scale-decreased backbone과 비교하여 큰 차이를 보여준다.
인접한 두 개의 intermediate blocks이 연결되어 deep pathway를 형성하는 것은 매우 일반적.
output blocks은 longer range connections을 선호하는 모습 보임.(??)
5.3. ResNetFPN vs. SpineNet
먼저 섹션 3.3에서 논의된 4개의 scale-permuted models 의 object detection 결과를 제시하고 ResNet50-FPN baseline과 비교한다.

Table 3:
(1) scale-decreased backbone model은 object detection를 위한 백본 모델의 좋은 설계가 아니다.
(2) scale-permuted model에 computation을 할당하면 더 높은 성능을 얻을 수 있다.
R50-FPN baseline과 비교하여, R0-SP53은 유사한 빌딩 블록을 사용하며, 학습된 scale permutations and cross-scale connections로 AP가 2.9% 높다.
SpineNet-49 모델은 FLOP를 10% 감소시킴으로써 효율성을 더욱 향상시키는 동시에 scale and block type adjustments을 추가하여 R0-SP53과 동일한 정확도를 달성한다.
5.4. Object Detection Results

RetinaNet: RetinaNet detector를 사용하여 COCO bounding box detection task에서 SpineNet 아키텍처를 평가
정확성과 효율성 모두에서 다양한 모델 크기에서 YOLO, ResNet-FPN 및 NAS-FPN과 같은 다른 인기 있는 detector를 큰 폭으로 능가한다.
가장 큰 SpinNet-190은 테스트 시간 확대 없이 단일 모델 객체 감지에서 52.1% AP를 달성

Mask R-CNN: SpineNet이 box detection and instance segmentation에서 Mask R-CNN으로 강력한 성능을 달성함을 보여준다.

Table 6: SpineNet 및 기타 백본(예: ResNet-FPN [8] 및 HRNet [33])의 val2017에 대한 성능 비교를 보여준다.
Mask R-CNN implementation에서 SpineNet의 성능을 측정
HRNet 성능은 opensourced implementation에서 채택.
RetinaNet 결과와 일치하게, SpinetNet은 FLOP 및 매개 변수를 적게 사용할 수 있지만 다양한 모델 크기에서 더 나은 AP 및 Mask AP를 달성할 수 있다.
SpinnNet은 box detection 시 RetinaNet을 통해 학습되지만 Mask R-CNN과 잘 작동한다.
Real-time Object Detection: Our SpineNet-49S and SpineNet-49 with RetinaNet run at 30+ fps with NVIDIA TensorRT on a V100 GPU.

Table 5: preprocessing, bounding box and class score generation , post-processing(후처리) with non maximum suppression(NMS)를 포함한 end-to-end object detection pipeline을 사용하여 inference latency 을 측정한다.
(30fps 영상이라고 생각했을 때, 가장 빠른 SpineNet-49S모델이 1초 영상을 detection하는 데에 3.51s가 걸리므로, 실시간에는 적합하지 않은 듯 하다.)
5.5. Ablation(절제) Studies
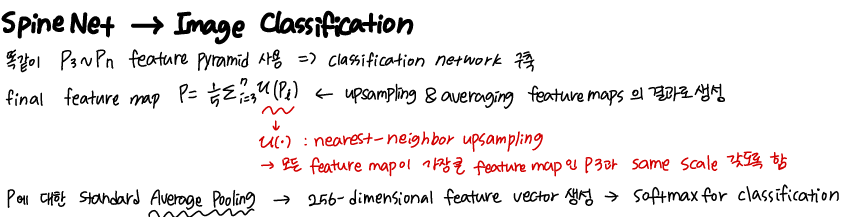
| Importance of Scale Permutation | 학습된 scale permutations을 fixed ordering feature scales와 비교하여 learning scale permutations의 중요성을 연구 encoder-decoder networks에서 널리 사용되는 두 가지 아키텍처 모양을 선택한다. (1) A Hourglass shape inspired by [27, 21];  (2)A Fish shape inspired by [34].  표 8은 모래시계 모양과 물고기 모양 구조에서 feature blocks의 순서를 보여준다. 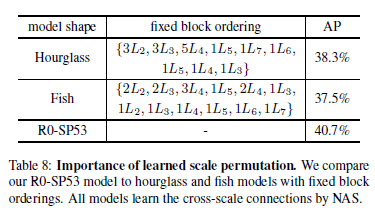 그런 다음 섹션 3.1에 설명된 동일한 search space를 사용하여 cross-scale connections을 학습한다. - learning scale permutations and cross-scale connections 이 fixed architecture shape로만 connections을 학습하는 것보다 더 낫다는 것을 보여준다. |
| Importance of Cross-scale Connections | cross-scale connections은 scale-permuted network 전체에 걸쳐 서로 다른 해상도에서 features를 융합하는 데 중요한 역할을 한다. graph damage을 통해 그 중요성을 연구. R0-SP53의 scale-permuted network의 각 블록에 대해 크로스 스케일 연결은 세 가지 방식으로 손상됩니다. 1) Removing the short-range connection; (2) Removing the long-range connection; (3) Removing both connections then connecting one block to its previous block via a sequential connection. 세 가지 경우 모두 한 블록은 다른 한 블록에만 연결됩니다.  표 9에서, 우리는 scale-permuted network가 여기서 제안된 모든 edge removal techniques에 민감하다는 것을 보여준다. (2)와 (3)은 (1)보다 더 심한 damage을 주며, 이는 short-range connection or sequential connection로 인해 빈번한 해상도 변화를 효과적으로 처리할 수 없기 때문일 수 있다. |
5.6. Image Classification with SpineNet
iNaturalist에서 SpineNet은 ResNet을 약 5%의 큰 차이로 능가
iNaturalist의 개선을 더 잘 이해하기 위해, iNaturalist-bbox를 생성(실제 실측 bbox에 의해 잘린 개체)
=성능 향상을 더 잘 이해하기 위해 각 이미지를 중심으로 상징적인 단일 스케일 개체가 있는 iNaturalist 버전을 만드는 것
사용 가능한 모든 bbox(물체 주위의 context를 포함하도록 crop 영역을 원래 bbox 폭과 높이의 1.5배 크기로 확대)를 잘라냈고, 그 결과 2,854개 클래스에서 496,164개의 훈련과 48,736개의 검증 이미지가 생성되었다.
iNaturalist-bbox에서 Top-1/Top-5 정확도는 SpinNet-49의 경우 63.9%/86.9%, ResNet-50의 경우 59.6%/83.3%이며, Top-1 정확도는 4.3% 향상되었다.
Top-1의 ResNet-50에 비해 SpineNet-49의 개선은 원래 iNaturalist 데이터 세트에서 4.7%이다.
실험을 바탕으로, 우리는 iNaturalist의 개선이 variant scales의 개체를 캡처하기 때문이 아니라 다음 두 가지 이유 때문이라고 생각한다.
1) SpineNet의 multi-scale features 으로 인한 미묘한 국소 차이(subtle local differences) 포착
2) 과적합 가능성이 낮은 more compact feature representation(256차원)
6. Conclusion
기존의 scaledecreased model이 simultaneous recognition and localization에 효과적이지 않음을 확인한다.
이 문제를 해결하기 위해 새로운 meta-architecture인 scale-permuted model을 제안한다. scale-permuted model의 효과를 입증하기 위해, 객체 감지에서 Neural Architecture Search(NAS)에 의한 SpinNet을 학습하고 이미지 분류에 직접 사용될 수 있음을 보여준다.
SpineNet은 COCO 테스트 개발에서 AP 52.1%에서 state-of-the-art object detection performance을 달성한다.
동일한 SpineNet 아키텍처는 훨씬 적은 수의 FLOP와 까다로운 iNaturalist 데이터 세트에서 5%의 상위 1위 정확도로 ImageNet에서 비교할 만한 상위 1위 정확도를 달성한다.
미래에는 scale-permuted model이 detection and classification를 넘어 많은 시각적 작업에 걸쳐 백본의 메타 아키텍처 설계가 되기를 바란다.
'Computer vision 논문 & 코드리뷰' 카테고리의 다른 글
| Unpaired Image-to-Image Translationusing Cycle-Consistent Adversarial Networks (CycleGAN) (0) | 2021.06.10 |
|---|---|
| SSD: Single Shot MultiBox Detector (0) | 2021.05.05 |
| Pix2Pix code review 코드리뷰 (0) | 2021.04.08 |
| [Pix2Pix]Image-to-Image Translation with Conditional Adversarial Networks (0) | 2021.03.30 |
| U-GAT-IT (0) | 2021.01.29 |