2021. 7. 15. 16:44ㆍComputer vision 논문 & 코드리뷰
Abstract
•Style transfer lecture에서 차용하여 GAN을 위한 새로운 Generator 아키텍쳐 제안
• 새로운 아키텍쳐는
1. 자동으로 학습됨
2. 높은 수준의 특징들(자세, 정체성 등)이 unsupervised seperation됨
• 생성된 영상의 stochastic variation(주근깨, 머리카락 등)으로 scale-specific control of the synthesis가 가능하게 한다.
• interpolation quality and disentanglement대한 정량적 표현을 위해 새로운 두가지 제안
1. perceptual path length
2. Linear separability
• 다양한 고품질의 새로운 인간 얼굴 데이터셋 소개 - FFHQ dataset

Progressive GAN = PGGAN을 baseline으로 소개하고 있고,
낮을 수록 성능이 더 좋다고 나타내는 FID점수를 통해 성능 향상을 나타내고 있습니다
bilinear up/down같은 interpolation방법 등의 tuning으로 FID를 낮추고,
매핑과 스타일을 추가하고, traditional input. 이 뒤에 소개하겠지만 stylegan에서는 gan에서 보통 사용하는 latent vector z를 바로 input으로 넣지 않고 중간벡터 w를 사용합니다.
그런의미에서 traditional input을 제거했다고 표현한 것 같고,
noise input 추가, mixing regularization또한 stylegan에서 제안하는 새로운 구조입니다.
이렇게 적용을 해주어서 성능이 좋아졌다고 나타내고 있습니다
BackGround
PGGAN?
해상도가 높은 데이터를 생성하도록 학습시키는 것은 매우 중요하지만 고화질이 될수록 D를 속이기가 힘들고 학습이 느려지기 때문에 낮은 해상도로 학습한 후 점진적으로 더 높은 해상도로 학습을 반복하는 것이 핵심

그림에서 볼 수 있듯이, 전체적인 공간정보부터 학습한 후 점차적으로 디테일을 학습해 간다.

- 모든 레이어는 동결시키지 않고 계속해서 같이 학습시킨다.
- G가 생성한 (다음 레이어에 비해) 저해상도인 이미지가 D에게 통과되면
G와 D의 레이어
(ex. 현재 16x16대상으로 학습했다면 32x32를 만들어내는 레이어)를 추가한다. - G와 D는 거울상 = 동시에 레이어 추가
- 새로운 레이어가 들어올 때 학습이 전혀 되지 않은 새로운 레이어의 간섭이 발생하지 않도록 하기 위해서 smooth fade in이 필요
smooth fade in?
위 figure의 (a) -> (b)의 과정으로 살펴보면
1. 16x16이미지를 두배로 upsampling 한 이미지(32x32)
2. 추가된 32x32레이어가 만들어낸 이미지
두 이미지를 합쳐주는데, 합쳐줄 때 2의 픽셀값에 a를 곱하고, 1의 픽셀값에 (1-a)를 곱해주어 합쳐줌으로써 저해상도의 전체적인 정보와 고해상도의 디테일을 합쳐준다.
a를 점점 증가시키면서 학습을 시키다가 a가 1일 때 학습이 잘 이뤄지면(D를 속이면) 다음 레이어 (64x64)를 추가해준다.
원하는 해상도가 될 때까지 이를 반복한다
AdaIN?
학습이 매우 느린 style transfer의 문제를 해결하기 위한 Normailize 방법
AdaIN = Adaptive Normalization
이미지 상에서 이뤄지는 것은 아니고, feature map 상에서의 연산이다.



entangle, disentangle

StyleGAN Generator


(a)는 전통적 GAN모델의 Generator(G라고 하겠다.)의 구조로, input으로 latent code z(보통 gaussian noise)가 들어가는 것을 볼 수 있다.
Noise의 형태를 살펴보기위해 이 부분 코드를 조금 살펴보면,
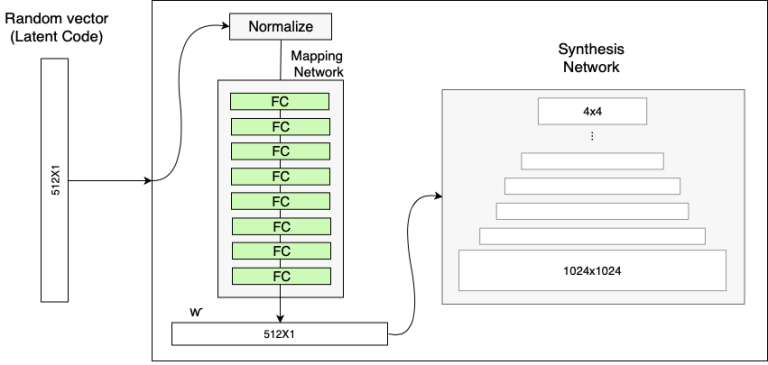
1.z = torch.randn(batch, 512) # 512는 latent_dim을 의미
2.w = 8-mlp(z) # w : (batch, 512) # mapping
3.x = torch.ones(1, 512, 4, 4) # Const 4x4x512, # feature
4.x = x + torch.randn(batch, 1, 4, 4) # x + noise
로 Noise는 (batch, 1, 4, 4) batchsize 무시하면 (1, 4, 4)의 형식으로 들어가서, Const인 x(그림의 4x4x512)에 더해준다. 채널마다 같은 노이즈를 더해주는 형태라고 생각하면 된다 (Noise는 single channel images, uncorrealted gaussian noise)

synthesis network g 부분을 보면
입력 부분을 완전히 생략했다.
-> 학습된 상수 (Const 4x4x512)에서 시작
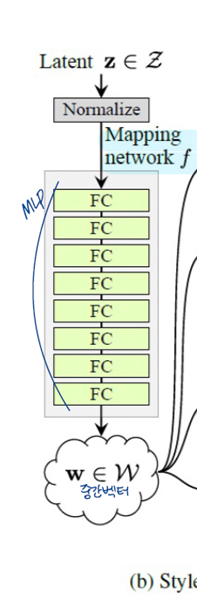
input latent space Z에 속한 latent code z를 MLP를 통과시켜
f: Z->W 라는 비선형적 매핑으로 w∈W를 생성
style y는 w로부터 affine transform 으로 얻어지는데, affine transform은 학습된다.
이렇게 얻어진 style y는 AdaIN을 컨트롤한다.
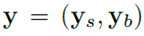
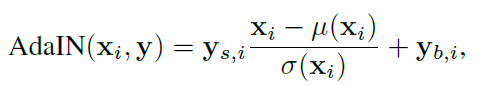
mapping network
기존 GAN처럼 input vector(gaussian distributio에서 samplin된 z)에서 바로 이미지를 직접 생성하면
input 분포(z는 보통 가우시안분포) 에 학습 이미지의 분포를 맞춰야 함.
시각적 특징들이 input space에 비선형적으로 매핑된다. (entangle)
latent space가 linear subspaces를 포함하도록 하는 것이 disentanglement의 목표
- 가우시안 분포를 샘플링한 z를 직접 사용하지 않고 계산된 w 벡터를 사용함
- 실제 학습 데이터는 모든 특징을 담고 있지 못함. 따라서, 가우시안 분포를 사용해 z 벡터를 만들면 갑작스럽게 특징이 바뀔 수 있음. 좀 더 선형적인 데이터 특징을 얻기위해 w 벡터를 계산함.
ex)

noise 상태인 latent space Z에서 바로 매핑을 진행하면
latent space가 (b)처럼 non-linear하게 mapping = entangle
머리가 검정이고 안경을 안 쓴 동양인을 생성할 수 없음

mapping network로 생성한 중간벡터 w의 공간인 W는
(c)처럼 특징이 학습 데이터 셋의 확률분포와 비슷한 모양으로 매핑 = 선형적매핑
latent space W는 disentangle하게 된다
disentangle을 정량적으로 평가하기 위한 두가지 지표를 제안
•Perceptual path length
•Linear separability
•Perceptual path length
- "어떤 특징들만 변화 하였는지"를 잘 구분을 할 수 있는지에 대한 방법을 자동화 시킨 개념
- pretrained VGG16 model의 중간 레이어의 feature map을 사용해 perceptual path length를 계산
G(z1) 과 G(z1+ϵ) 를 pretrained VGG16에 넣은 결과의 pairwise image distance값이 크다면 latent space가 entangle하다고 판단


entangle한 a의 경우 z가 변하면 남성 -> 여성 이렇게 극단적인 결과가 발생하지만
disentangle한 b의 경우 선형적으로 학습데이터와 유사한 분포로 매핑되어 있기 때문에 z가 똑같이 변해도 아주 조금의 변화만이 일어난다.
•Linear separability
latent space가 충분히 disentangle되었다면 stochastic variation(머리카락 색, 수염 등 )을 설명할 수 있는 latent vector z의 direction vector(ex.머리카락 색이 변화하는 방향)를 정확하게 찾아낼 수 있을 것이라는 것에서 나온 개념
Synthesis Network


W가 style에 영향을 주면서 동시에 normalization 해주는 방법
= AdaIN
x_i는 각각 정규화된 후 y_si로 scale되고 y_bi로 biased된다
따라서 y차원수는 그 레이어 feature map 차원수의 2배 – channel wise니까

W가 AdaIN을 통해 style을 입힐 때 shape이 안 맞아 Affine Transformation을 거쳐서 shape을 맞춰줌
AdaIN에서 정규화를 할 때 마다 한 레이어 당 한번씩 개별적으로 W가 영향을 미치므로
하나의 style이 각각의 scale에서만 영향을 끼칠 수 있도록 분리하는 효과
-> AdaIN이 style을 분리하는 방법으로 효과적이다

1x512인 w가 style로 변형되는 affine transformation은 학습된다
그림에 오른쪽에 자세히 나온 부분은 conv 레이어부터의 부분인데,
앞의 upsample – AdaIN의 경우도 비슷하게 돌아간다고 보면 될 것 같다.
일단 outputshape는 (r x r x 512)로 계속 동일하게 나오는 듯
이렇게 w차원수의 두배인 y가 나오게 되고 AdaIN이 적용된다.
정리
●synthesis network의 각 layer마다 AdaIN으로 style을 normalize한 후 또 새로운 style을 입히게 되므로 특정 레이어에서 입혀진 style은 바로 다음 conv layer에만 영향을 미침
->각 레이어의 style이 특정 시각적 특징만 담당하게 됨
●style을 조정한다는 것 == 이미지의 global information을 통째로 조정하는 것
-> spatially-consistent한 이미지를 얻게 되어 기존의 G보다 훨씬 안정적이고 자연스러운 이미지를 얻을 수 있다.
Style Mixing


이후 이 그림처럼 한 스케일 네트워크 당 적용해도 되고
두 레이어 당 하나 이렇게 적용해도 되고
이러한 방식이 style mixing


Stochastic Variation

같은 사람에 대한 이미지라 할지라도 머리카락, 수염, 주름 등 stochastic하다고 볼 수 있는 요소 많이 존재
synthesis network 각 레이어마다 추가되는 random noise는 이러한 stochastic 정보를 담당

왼쪽 그림의 (b)는 input noise의 변화에 따른 머리카락의 미세한 변화를 보여주고 있다.
-> 전체적인 외형이나 정체성은 비슷하나, 머리카락의 위치가 매우 다르게 나타나고 있다.
(c)는 노이즈의 영향을 받는 영상 부분을 강조한 그림이다.
주요 부위는 머리카락, 실루엣, 배경 일부이지만, 눈 반사에도 흥미로운 확률적 변화가 있다.
-> 전체적인 인종, 성별, 자세 이런 것들은 노이즈의 표준편차(가우시안 노이즈 이니까) 에 큰 영향을 받지 않지만 머리카락 방향이라던지 이런 작은 부분들이 영향을 받는다!
이를 이용하여 미세한 리터치 (머리카락을 길게한다던지?)가 가능

(a)모든 레이어에 노이즈 적용
(b) 노이즈 x
(c) fine layer들에만 노이즈 적용(64x64~1024x1024)
(d) coarse layers(4x4~32x32) 에만 노이즈 적용
noise를 많이 줄수록 모발이 더 곱슬곱슬하고 noise가 작으면 곱슬거리는게 덜하고 미세한 배경 디테일이나 피부모공 등을 만들어낸다
Conclusion
•전통적 gan의 generator 의 구조보다 style gan에서 제안하는 generator의 구조가 훨씬 결과가 좋다.
•high level attributes와 stochastic effects의 분리와 intermediate latent space의 선형성에 대한 조사가 GAN 합성에 대한 이해와 제어 가능성을 개선하는 데 도움이 될 것.
•average path length metric은 training동안 regularizer로서 쉽게 사용될 수 있음
•training동안 intermediate latent space을 직접 shaping하는 방법들이 미래의 작업들에 흥미로운 수단을 제공할 것이라고 기대