2020. 12. 14. 16:02ㆍmachine learning
※ 본 카테고리의 글은 책<파이썬머신러닝완벽가이드(권철민)> 및 다른 자료들을 참고하여 작성되었습니다. ※
github:github.com/chaeyeongyoon/PythonML_Study
chaeyeongyoon/PythonML_Study
Contribute to chaeyeongyoon/PythonML_Study development by creating an account on GitHub.
github.com
기본적으로 머신러닝은
- dataset분리 ( train, test )
- Machine Learning Algorithm 적용 ( model training )
- prediction
- evaluation
순으로 진행됩니다.
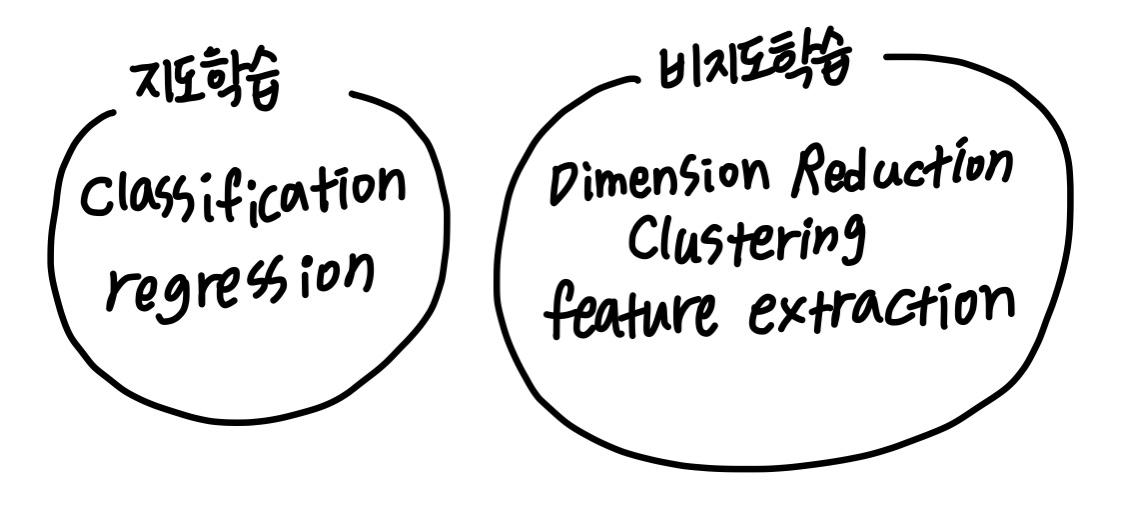
크게 지도학습과 비지도학습으로 분리됩니다.
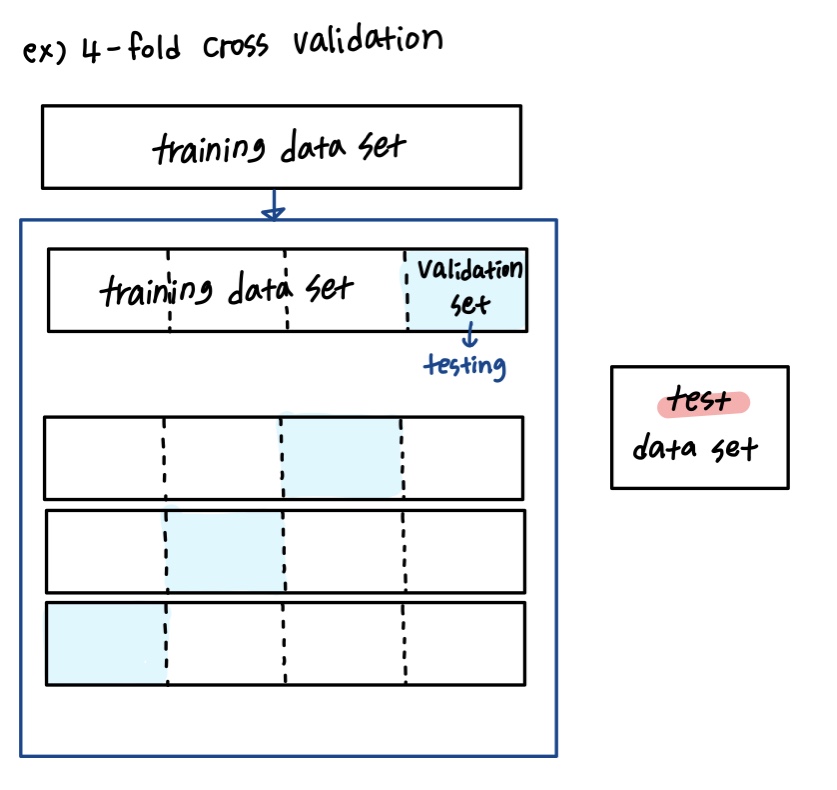
● 교차검증 ( Cross Validation )
overfitting을 방지하는 한 방법입니다.
overfitting이란 모델이 학습데이터 또는 test데이터에만 과도하게 적합한 것
1. K-fold cross validation
2. Stratified K-fold
보통 분류에서 사용하는 교차검증이다.
imbalanced 분포를 가진 label data 집합에 사용한다. 원본 데이터 label의 분포를 고려하여 이 분포와 동일하게 분배합니다.
☆ sklearn의 GridSearchCV class를 사용하면 교차검증과 최적하이퍼파라미터 튜닝까지 함께 할 수 있습니다.
● Preprocessing(전처리)
1. NaN, Null값을 대체하거나 drop해야합니다.
2. 문자열은 숫자형으로 변환해주어야 합니다. 카테고리형은 Label incoding이나 one-hot encoding 적용,
텍스트형은 피쳐벡터화를 해주거나 drop해줍니다.
3. feature scaling : 변수의 값 범위를 일정 수준으로 맞춰줍니다.

● Evaluation ( 평가 )
모델의 성능평가 지표에는 여러가지가 있습니다. 보통 accuracy를 사용하지만 accuracy만으로는 잘못된 평가를 할 가능성이 높기 때문에 (특히 imbalanced label 분포에서) 다른 지표들을 많이 사용합니다.
1. 오차행렬
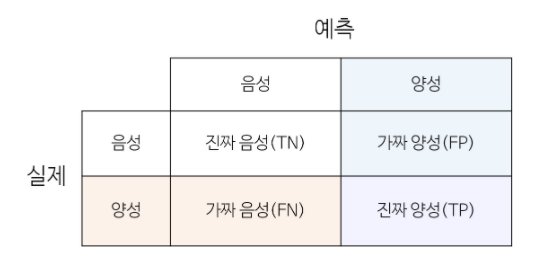
2. accuracy = (TN + TP) / (TN + TP + FN + FP)
예측값과 실제 값이 같은 비율을 나타냅니다.
3. 정밀도 / 재현율 ( precision / recall )
precision = TP / (FP + TP) : 전체 예측값 P중에 실제 P비율. 실제 P를 N으로 판단하면 큰 영향이 발생할 때 중요지표로 사용합니다. ex) 암=P, 음성=N일 때
recall = TP / (FN + TP) : 실제 P/중에 P로 예측한 비율. 실제 N을 P로 판단하면 큰 영향이 발생할 때 사용합니다.
ex) 스팸메일: P, 정상메일: N일 때
정밀도와 재현율은 trade-off 관계를 가집니다. 둘다 적당한 값을 가지도록 threshold를 조정해야 합니다.
(Threshold : 이진분류 임계값. 임계값을 넘는 경우 1로 판단한다.)
보통 threshold가 낮아지면 recall 은 높아지고 precision은 낮아집니다.
4. F1 score
F1 score은 recall 과 precision이 어느 한 쪽으로 치우치지 않을 때 높은 수치를 가집니다.

5. ROC Curve, AUC
ROC는 Receiver Operation Characteristic 을 뜻하며 원래 통신장비성능지표로 많이 사용되고 의학분야에도 많이 사용한다. FPR이 변할 때 TPR이 어떻게 변하는지 나타내는 곡선입니다.
FPR = FP / (FP + TN) = 실제 N 중 P로 판단한 비율, TPR = recall = sensitivity = TP / (FN+TP)
※ TNR은 TPR과 대응하는 개념으로 specificity라고도 불린다. TNR = TN / (FP + TN) : 실제 N 중 N으로 판단한 비율
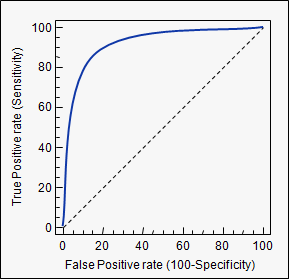
직선에서 멀어질수록 성능이 좋은 것입니다.
FPR을 0에서 1로 변화시켜가면서 TPR의 변화를 관찰합니다.(Threshold를 변화시키면서)
'machine learning' 카테고리의 다른 글
| Clustering(군집화) (0) | 2020.12.15 |
|---|---|
| 차원축소 (Demension Reduction) (0) | 2020.12.14 |
| Regression (회귀) (0) | 2020.12.14 |
| Classification (0) | 2020.12.14 |