2021. 1. 9. 13:06ㆍComputer vision ღ'ᴗ'ღ
※ 본 글은 <딥러닝 컴퓨터비전 완벽가이드> 강의 및 여러 자료를 참고하여 쓰여진 글입니다. ※
github: github.com/chaeyeongyoon/ComputerVision_Study
chaeyeongyoon/ComputerVision_Study
Contribute to chaeyeongyoon/ComputerVision_Study development by creating an account on GitHub.
github.com
YOLO는 이미지 내의 bounding box와 class probability를 single regression problem으로 간주하여, 이미지를 한 번 보는 것으로 object의 종류와 위치를 추측합니다.
가장 최신버전인 YOLO v3은 빠른 속도와 높은 성능을 보여줍니다.

| v1 | v2 | v3 | |
| 원본이미지 크기 | 446x446 | 416x416 | 416x416 |
| feature extractor | Inception 변형 모델 | darknet 19 | darknet 53 |
| grid당 anchor box 수 | anchorbox기반 아님 | 5 | output feature map당 3개 서로 다른 크기와 scale로 총 9개 |
| anchor box 결정 방법 | 고정 | K-means clustering (고정되어있지 않고 GT Box를 분석) |
K-means clustering (고정되어있지 않고 GT Box를 분석) |
| output feature map 크기 (depth제외) |
13x13 | 13x13, 26x26, 52x52 3개의 feature map 사용 |
|
| feature map scaling 기법 | FPN (Feature Pyramid Network) |
yolo v1부터 살펴보겠습니다.
● YOLO v1
yolo v1은 PASCAL VOC dataset 기반으로 학습되었는데, 빠른 detection시간을 자랑하지만 정확도는 비교적 낮습니다.
- 입력이미지를 SxS grid로 나누어 각 grid cell이 하나의 object대한 detection을 수행합니다. (feature map이 아닌 원본 이미지 기준임을 주의하세요)
- 각 grid cell이 2개의 bounding box후보를 기반으로 object bounding box를 예측합니다.(anchor box기반이 아닙니다)
v1의 inference 방식은 다음과 같습니다.

GoogLeNet modication은 GoogLeNet을 수정해 classification모델로 만든 것 입니다.
최종적으로 나오는 7x7x30 shape는 7x7 = grid개수, 30=각 grid가 갖는 정보 개수 입니다.
30개의 정보는
- 2개의 bounding box정보 (x, y, w, h, confidence score) (x, y, w, h는 GT box와 후보 box간 offset)
- class확률 (PASCAL VOC기준이므로 20개의 class확률)
- 5x2+20 = 30입니다.

다음 그림과 같이 SxSx2개의 bounding box를 예측한 후 NMS로 걸러줍니다.
one stage object detection의 특징인 일단 많은 bounding box를 예측하는 특징이 드러납니다.
※ NMS로 최종 bounding box 예측하는 과정
- 특정 confidence 값 이하는 모두 제거
- 가장 높은 confidence 갖는 순으로 bounding box 정렬
- 가장 높은 confidence 갖는 bounding box와의 IOU가 IOU threshold보다 큰 bounding box는 모두 제거
- 남은 bounding box대해 3번 반복
즉 Object confidence와 IOU threshold로 filtering을 조절합니다.
그러나 v1은
<단점>
- anchor box기반이 아니고, 단순 cell기준이기 때문에 성능은 낮고 복잡합니다.
- yolo(you only look once)라는 이름답게 한 cell에서 object 하나를 발견하면 바로 다음 cell로 넘어가버리기 때문에 속도는 빠르지만 성능은 낮습니다.
- 작은 object대한 성능이 특히 떨어집니다.
● YOLO v2
v2의 성능은 다음 표와 같습니다.

v2의 특징은 다음과 같습니다.
- Batch Normalization
- High Resolution Classifier : Network의 classfier단을 보다 높은 resolution(448x448)로 fine tuning (매우 좋은 효과를 보였습니다)
- 13x13 feature map기반에서 개별 grid cell 별 5개의 anchor box에서 object detection
- Darknet-19 Classification model 사용
- 서로 다른 크기의 image들로 network 학습 ( 작은 object 성능 저하 문제 해결을 위해 )

yolo v2의 구조상 가장 큰 특징은 Fully Connected layer가 없다는 것입니다.
SSD와 유사하게 1cell에서 anchor box를 통해 여러개의 object를 detection합니다.
K-means clustering을 통해 data set의 이미지 크기와 shape ratio따른 5개의 군집화 분류로 anchor box를 계산합니다.
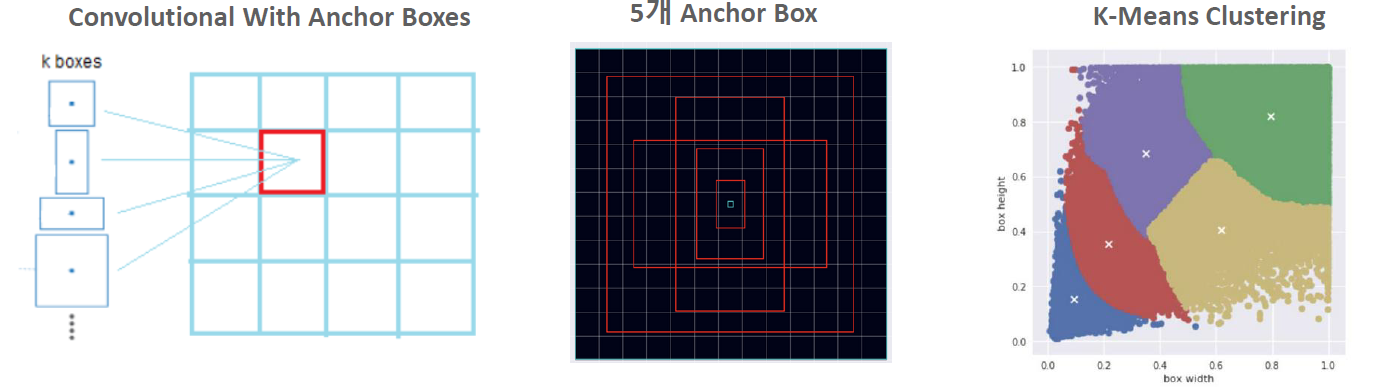
v2의 ouput feature map을 살펴보면

다음과 같은 shape를 갖는데, 하나의 anchor box당 25개의 정보를 갖습니다.
- bounding box 좌표정보 4 + Objectness score 1 + classes scores(PASCAL VOC: 20) = 25
- objectness score은 object일 확률을 뜻합니다.
● YOLO v3
- Feature Pyramid Network 유사한 기법 적용해 3개의 feature map output에서 각각 3개의 서로 다른 크기와 scale 갖는 anchor box로 detection
- classification 단을 보다 높은 classification을 갖는 darknet-53
- Multi Labels 예측: softmax아닌 sigmoid기반의 logistic classifier로 개별 object의 multi labels예측: 즉, people-woman이런식의 multi label예측이 가능합니다.
<v3 Network 구조>
- input size를 꼭 (416, 416) 으로 조정해주어야 합니다.
- darknet구조는 skip connection이라는 특징을 갖습니다.
- 13x13, 26x26, 52x52의 featuremap에 각각 anchor box를 적용해 줍니다.


다음 그림을 보면,
- 큰 feature map일수록 작은object를 detection가능하다.
- bounding box 하나당 85개의 정보를 갖는다
- 좌표정보 4 + objectness score + class scores(coco dataset 기준이라 80개)
잠시 darknet에 대해 언급을 하자면 ResNet과 비슷한 구조를 갖는데, yolo의 성능을 높이기 위해 독자적 network인 darknet을 개발하기 위해 노력을 많이 했습니다.
<Training>
yolo v3 training에는 multi-scale training, data augmentation을 적용하였습니다.
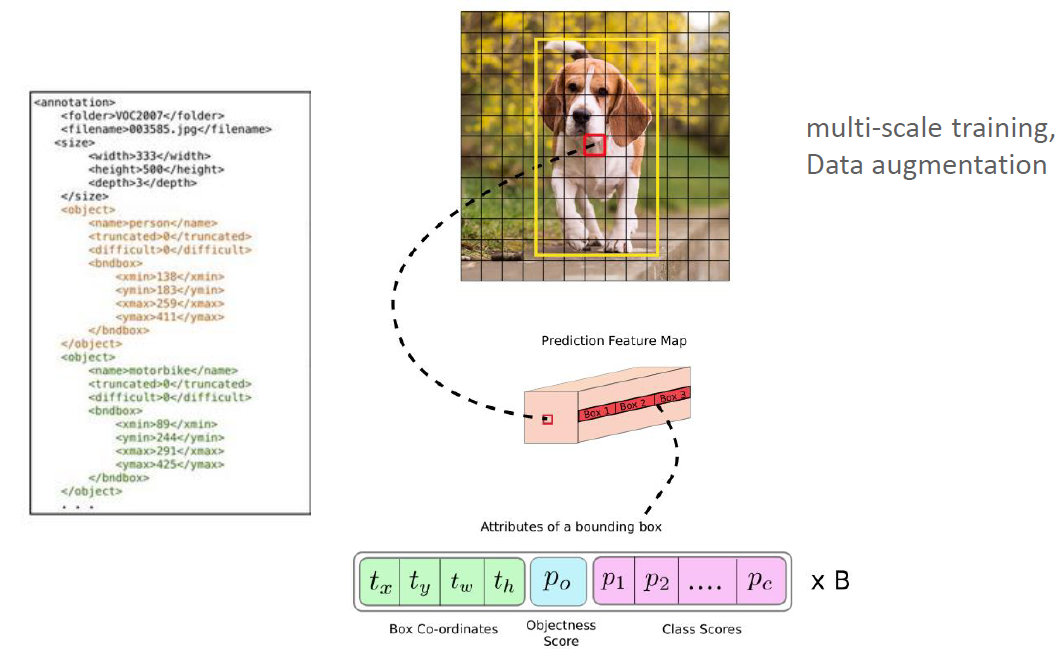
annotation file의 GT box를 기준으로 bounding box regression학습
bounding box regression(Lacation Prediction)을 간단히 표현하면 다음과 같습니다.

- (pw, ph) : anchor box size
- (tx, ty, tw, th): 모델 예측 offset값
- (bx, by), (bw, bh) : 예측 bounding box 중심좌표, size
center좌표가 cell 중심을 너무 벗어나지 못하게 sigmoid값으로 조절합니다
<multi label>

softmax를 사용하면 하나의 class만 detection할 수 있는데, 여러개의 독립적 logistic regression과 sigmoid를 사용하면 여러개의 class를 labeling할 수 있습니다.
<v3 성능>

'Computer vision ღ'ᴗ'ღ' 카테고리의 다른 글
| google Open Image dataset 사용해 YOLO training / OID_v3_toolkit 사용하기 (0) | 2021.01.22 |
|---|---|
| keras-yolo3 opensource package (0) | 2021.01.22 |
| SSD Network (0) | 2021.01.08 |
| Fast R-CNN, Faster R-CNN (0) | 2021.01.03 |
| SPPNet (0) | 2021.01.03 |