2020. 12. 23. 12:47ㆍComputer vision ღ'ᴗ'ღ
※ 본 글은 <딥러닝 컴퓨터비전 완벽가이드> 강의 및 여러 자료를 참고하여 쓰여진 글입니다. ※
github: github.com/chaeyeongyoon/ComputerVision_Study
chaeyeongyoon/ComputerVision_Study
Contribute to chaeyeongyoon/ComputerVision_Study development by creating an account on GitHub.
github.com
Object Detection(객체 인식)은 Deep learning이 발전함과 함께 빠른속도로 성장했습니다.

object detection에서 localization, detection, segmentation의 차이는 뭘까요?
classification은 하나의 객체가 있는 영상의 class를 찾아주는 것이고,
localization은 말 그대로 하나의 object가 있는 영상에서 object의 위치를 찾아내는 것입니다.(Bounding box단위)
Detection은 여러 object가 있는 영상에서 각 object 위치를 찾아내고, 무슨 객체인지(class) 인식하는 것(Bounding Box 단위) 까지인데, segmentation은 픽셀단위 detection이라고 할 수 있습니다.

Localization과 Detection은 해당 object의 위치를 Bounding Box로 찾고, Bounding Box 내 object를 판별하는데,
즉 bounding box regression과 classification 두가지 문제가 합쳐진 것이라고 할 수 있습니다.
Detection은 두개 이상의 object를 이미지의 임의의 위치에서 찾아야해 상대적으로 더 어렵습니다.
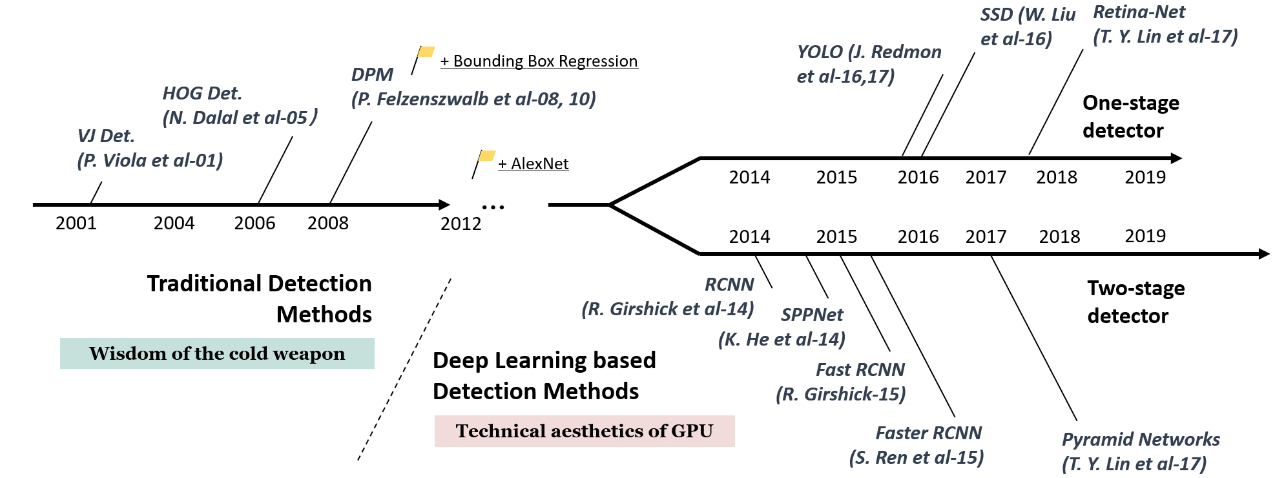
object detection의 발전을 살펴보면 아래 그림에서 보이듯이 딥러닝기반 기술이 빠르게 발전해 왔습니다. 그 중에서도 두가지 방법으로 나뉘는데, One-stage detector 과 Two-stage detector입니다.
Two-stage detector은 1. detection 위한 object를 추천하고, 2. classification과 bounding box를 그리는 두가지 단계로 이루어져 실시간 detection은 좀 어렵습니다.
그에 반해 One-stage detection은 한단계로 한번에 이뤄지기 때문에 실시간 처리가 가능합니다.
그 중 YOLO를 최근 가장 많이 사용합니다.
RCNN과SPPNet은 서로를 기반으로 발전하였습니다.
각 detector의 자세한 내용은 나중에 따로 포스팅 하겠습니다.
● Object Detection의 주요 구성
1. 영역추정 (Region Proposal)
2. Detection위한 Deep Learning network 구성 : Feature Extraction과 Network Prediction의 역할
3. 그 외 IOU, NMS, mAP, Anchor Box 등
● Object Detection의 난제
- 이미지에서 여러개의 물체를 classification함과 동시에 위치를 찾아줘야합니다.
- 다양한 크기와 유형의 object들이 섞여있기 때문에 Detection에 어려움을 겪습니다.
- 시간이 중요한 실시간 영상 기반에서 detect를 하려면 요구사항이 많아집니다.
- object image가 명확하지 않은 이미지나, 배경이 대부분을 차지하는 이미지에서는 객체를 찾기가 어렵습니다.
- 딥러닝 네트워크를 학습시킬 데이터 세트가 부족합니다. 학습시키려면 annotation을 만들어야해서 데이터 세트 생성이 어렵습니다.
※ annotation? bounding box위치 및 여러 정보가 담긴 txt 파일
'Computer vision ღ'ᴗ'ღ' 카테고리의 다른 글
| R-CNN(Regions with CNN) (0) | 2021.01.03 |
|---|---|
| COCO dataset 다루기 (0) | 2020.12.26 |
| 주요 dataset 및 파이썬 이미지 라이브러리 (0) | 2020.12.23 |
| IOU /NMS/mAP (0) | 2020.12.23 |
| Localization / Detection / Segmentation (0) | 2020.12.23 |